10-软件体系结构设计与构建
- 体系结构之间的接口:
- 重点还有根据分配的需求确定模块的对外接口
- 初步设计关键类
- 编写接口规范(提供服务和需要服务)
- 根据体系结构开发继承测试用例(Stub和Driver)
- 1. 体系结构设计过程(简略步骤) 重要
- 2. 第一步:分析关键需求和项目约束
- 3. 第二步:通过选择体系结构风格
- 4. 第三步:进行软件体系结构逻辑(抽象)设计
- 5. Package Design Principles 包设计原则
- 5.1. Common Closure Principle (CCP) 共同封闭原则
- 5.2. Common Reuse Principle (CRP) 共同重用原则
- 5.3. 共同封闭原则和共同重用的原则的折衷
- 5.4. Reuse-Release Equivalency Principle (REP) 重用发布等价原则
- 5.5. The Acyclic Dependencies Principle (ADP) 无环依赖原则
- 5.6. Stable Dependencies Principle (SDP) 稳定依赖原则
- 5.7. 包的稳定性度量
- 5.8. Stable Abstractions Principle (SAP) 稳定抽象原则
- 5.9. 包设计的过程
- 6. 第四步:依赖逻辑设计进行软件体系结构(实现)设计;
- 7. 第五步:完善体系结构设计
- 8. 第六步:添加构件接口
- 9. 体系结构的原型构建
- 10. 体系结构集成与测试
- 11. 体系结构文档化
- 12. 体系结构评审
1. 体系结构设计过程(简略步骤) 重要
- 分析关键需求和项目约束:分析用例文档和需求规格说明书(包含需求规格和项目约束)。注意既要考虑功能性需求,又要考虑非功能性需求,甚至很大意义上体系结构设计是为了满足非功能性需求【质量属性】。
- 通过选择体系结构风格:选择分层风格(信息系统、并行开发、非web应用),进行评审。
- 进⾏软件体系结构逻辑(抽象)设计:产生逻辑包图
- 依赖逻辑设计进行软件体系结构(实现)设计:产生物理包图/开发包图
- 完善体系结构设计:关键类图,持久化数据格式的定义等
- 添加构件接口:包、重要文件的创建,定义接口
- 迭代过程3-6
- 步骤1-3是逻辑设计,步骤4-7是物理设计
- 本文接下来的部分将要按照这个思路进行下去
2. 第一步:分析关键需求和项目约束
- 一般来说,体系结构设计的输入要素主要由两个来源:
- 软件需求规格说明
- 项目约束
- 体系结构设计必须落实所有的功能性需求和非功能性需求
2.1. 系统结构需求

2.2. 实践案例
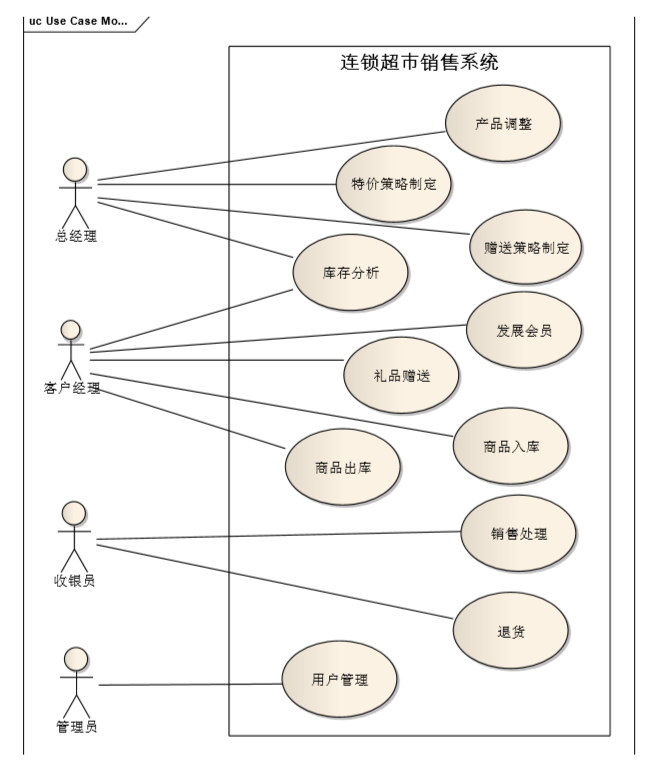
- 需求
- a 概要功能需求:10 个功能
- b 非功能性需求
- 安全需求:Security1~3
- 约束:IC2
- 项目约束
- a 开发技术:Java
- b 时间较为紧张
- c 开发人员:不熟悉 Web 技术
3. 第二步:通过选择体系结构风格
3.1. 实践案例

- 分层风格
- 协议不变情况下易于修改
- 能够促进并行开发:只需要界定好层与层之间的接口
4. 第三步:进行软件体系结构逻辑(抽象)设计
逻辑设计的目的是建立能够满足概要功能需求、质量需求和项目约束的软件体系结构逻辑设计
4.1. 依据概要功能需求与体系结构风格建立初始设计
- 将需求分配到子系统和模块
- 考虑功能的相同性:不同任务,但是相同功能
- 考虑可复用性:结构、数据、行为的可复用性


-
销售是否只用到Sale的数据:显然不是,即一个模块内的信息可能在多个模块中会重复的出现,软件设计的结果中不能将相同的信息或行为同时分布在多个地方,所以对上述的信息或行为相同的情况,可以将信息或行为放在一个模块中,让其他的模块依赖于该模块即可
下图中的显示部分用UI后缀,持久层用Data后缀(指包名)

- 连锁超市管理系统的改进概要功能设计,应该将需要的信息补充上

-
初步设计方案一:
层与层之间的交互很复杂

- 初步设计方案二:
-
层与层之间就是一一对应了。
-
逻辑层对象进行一一交互,只要互相对应的进行通知即可。
将交互放在了组内,组间的交互一定比组内交互要麻烦困难
-
进一步将业务层的功能进行切割划分
-

4.2. 使用非功能性需求与项目约束评价和改进初始设计
4.2.1. 初步设计的分析
- 能够满足项目约束:
- 分层风格能促进并行开发,从⽽缩短开发时间;
- 分层风格可以使⽤ Java 技术,⽽不使⽤ Web 技术。
- 无法满足安全需求(Security1~3)和网络分布约束(IC2),所以需要改进:
- 为使其满足安全需求,可以增加用户登录与验证功能,可以建立专门的三个模块 (Presentation、Logic、 Data),也可以将该功能并⼊⽤户管理功能,即为 userui, user, userdata 三个模块增加新的职责。
- 为满足网络分布约束,需要将模块分布到客户端和服务器组成的网络上。
- 可以将 Prensentation 层模块部署在客户端,将 Logic 层和 Data 层的模块部署在服务器端。[瘦客户端]
- 也可将 Prensentation 层和 Logic 层模块部署在客户端,将 Data 层的模块部署在服务器端。[胖客户端]
- ⼀旦相邻两层被部署到网络两端,那么它们之间的交互就⽆法通过程序调⽤来完成,可以考虑将简单的程序调⽤转化为远程⽅法调⽤ RMI(Remote Methods Invocation)或者HTTP。
- 连锁超市管理系统最终的软件体系结构逻辑设计⽅案


5. Package Design Principles 包设计原则(带英文关键)
- 重用发布等价原则(REP):重用的粒度就是发布的粒度
- 共同封闭原则(CCP): 包中所有类对于同一类性质的变化应该是共同封闭的,一个变化若对一个包产生影响,则对该包中的所有类产生影响,而对于其他包不造成任何影响。
- 共同重用原理(CRP):一个包中的所有类应该是能够共同重用的。
- 无环依赖原则(ADP):在包的依赖关系图中不能存在环。
- 稳定依赖原则(SDP):朝着稳定的方向进行依赖
- 稳定抽象原则(SAP):包的抽象程度应该和其稳定程度一致
- 前三条描述的是依赖性,后三条描述的是耦合性

5.1. Common Closure Principle (CCP) 共同封闭原则
- 一起修改的类应该放在一起 class which change together belong together
- 最小化修改对程序员的影响
- 当需要更改时,对程序员有利
- 如果更改由于编译和链接时间以及重新验证而影响了尽可能少的软件包
- 示例

- 总结
- 将具有相似闭包的类分组
- 面向可以预期的变更封闭包
- 将更改限制为几个软件包,这样会使得软件包的合并,得到更大的包[比如要修改的全部可以放在一个包中]
- 降低包装释放频率
- 减少程序员的工作量
- 只对可预测的变更有作用,不可预测的变更会为系统带来极大的破坏能力,并且无法进行预测。
5.2. Common Reuse Principle (CRP) 共同重用原则
- 一起被重用的应该在一起 class in packages should be reused together[如数学运算的函数应该一起放在一个math包]
- 包应重点突出,用户应使用包中的所有类
- 总结
-
根据常见重用对类进行分组:避免给用户不必要的依赖
(即包中包含不是经常用到的功能,但其他功能常用,那么不合适,导致对不常用功能造成依赖)因此会导致下面2.
-
遵循CRP通常会导致软件包拆分:获得更多,更小,更专注的包
-
减少重新使用者的工作
-
5.3. 共同封闭原则和共同重用的原则的折衷
- CCP和CRP原则是互斥的,即不能同时满足它们。
- CRP使重用者的生活更加轻松,而CCP使维护者的生活更加轻松。
- CCP致力于使包装尽可能大,而CRP则尝试使包装很小。
- 在项目的早期,架构师可以设置包结构,使CCP占主导地位,并协助开发和维护。后来,随着体系结构的稳定,架构师可以重构程序包结构,以使外部重用程序的CRP最大化。
- 也就是说在软件开发的不同阶段CCP和CRP的重视重用程度时不同的,要根据项目进展来进行不同程度的学习。
5.4. Reuse-Release Equivalency Principle (REP) 重用发布等价原则
-
重用的单位是发布单位 the unit of reuse is unit of release
[比如加减乘除,加法已经第三个版本了,但减法仍然是第二个版本,那么两者可能不能通用,发布后使用起来会有问题]
-
是关于重用软件的
-
可重用软件是外部软件,您可以使用它,但其他人可以维护它。
-
商业和非商业外部软件之间的重用没有区别。
-
例子

- 总结
- 为重用器分组组件(类)
- 单个类通常是不可重用的:几个协作类组成一个包
- 包中的类应构成可重用和可发布的模块:模块提供一致的功能
- 减少重新使用者的工作
- 和相关联的类一起发布,而不是单独进行发布
5.5. The Acyclic Dependencies Principle (ADP) 无环依赖原则
- 程序包的依赖关系结构必须是有向无环图(DAG) the dependency structure for packages must be a Directed Acyclic Graph
- 稳定并分批发布项目
- 以自上而下的层次结构组织程序包依赖关系
- 一旦形成环就可能会形成无限的修改(环中的包的修改会导致大量的修改的发生)
5.5.1. Dependencies are a DAG

- 左侧这个树就形成了环状结构
5.5.2. 依赖循环打破循环:第一种方式:
- 这种情况是单向依赖产生的闭环
- 一种解决方案:将Common error依赖的一个GUI中的一个包从GUI中抽取出来,如MessageManager 这样GUI依赖于MM,common error 也依赖于MM,就可以避免循环依赖的出现了。

5.5.3. 依赖循环打破循环:第二种方式:
- 另一情况,这种情况是互相依赖产生的闭环,A依赖于X,Y依赖于B。左边包发生更改,右边包一定要改,而因为右边包发生更改,那么左边包仍然要改,无限循环。【注意不能以为只是改了一个X或者Y,包内的内容是有联系的,根据CCP,X改了,Y可能也变更】
- :star:解决方案:从Y提供一个接口,这个接口被B实现,Y依赖于这个接口。在Y中只会在BY b = new B();时出现B,其他的时候一定都是BY,因此这不是完全的不依赖,而是一种弱的依赖。因此出现spring中的依赖注入,通过autowired,在Y中完全不需要出现B,也就不存在依赖了,创建B的过程都与Y无关,而是交给spring去做
- B实现BY:思考方式:在B中会出现BY,但BY中不会出现B,因此是B依赖于BY
- 所以通过修改使得B依赖于BY,左边依赖于右边了,左边发生更改,右边不需要做任何更改(B发生任何改变,只要他实现了BY接口,那么Y都不需要更改)

5.5.4. 无环依赖原则的应用场景
- 层次式风格和主程序/子程序风格通常不会产生
- ⾯向对象式风格尤其要注意
- C/S的MVC风格可能会发⽣
- 基于数据流、事件/消息、数据共享进行交互的体系结构风格通常不会发⽣
5.6. Stable Dependencies Principle (SDP) 稳定依赖原则
- 依赖应当指向一个稳定的方向(更改他所需要付出努力) dependencies should point in the direction of stability
- 稳定性:对应于更换包装所需的时间
- 稳定的软件包:项目内难以更改
- 稳定性可以量化
5.6.1. example
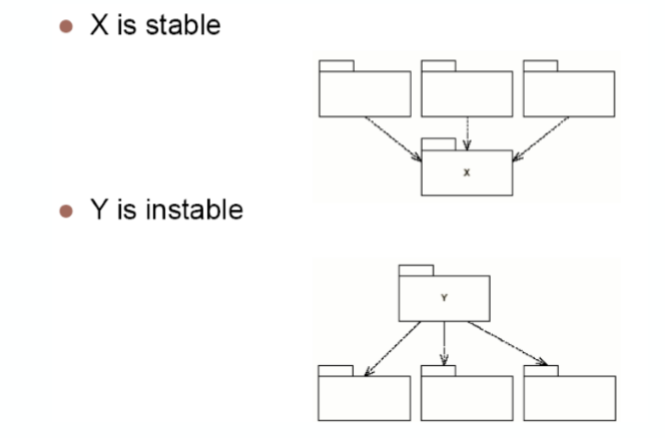
- 为什么X是稳定的,而Y是不稳定的(对于x,别人变化不会影响到x)

5.6.2. 包的稳定性度量
- 一种方法是计算进、出该包的依赖关系的数目。可以使用这些数值来计算该包的位置稳定性(positional stability)。
- (Ca)输入耦合度(Afferent Coupling):指处于该包的外部并依赖于该包内的类的类的数⽬。
- (Ce)输出耦合度(Efferent Coupling):指处于该包的内部并依赖于该包外的类的类的数⽬。
- (不稳定性I)I = Ce / (Ca + Ce)
- 该度量的取值范围是[0,1]。I=0表示该包具有大的稳定性。I=1表示该包具有大的不稳定性。通过计算和⼀个包内的类有依赖关系的包外的类的数⽬,就可以计算出实体 Ca 和 Ce 。
- 当⼀个包的I度量值为1时,就意味着没有任何其他的包依赖于该包(Ca = 0);⽽该包却依赖于其他的包(Ce>0)。这是⼀个包不稳定的状态:它是不承担责任且有依赖性的。因为没有包依赖于它,所以它就没有不改变理由,而它所依赖的包会给它提供丰富的更改理由。
- 另⼀方面,当⼀个包的I度量值为0时,就意味着其他包会依赖于该包(Ca > 0),但是该包却不依赖于任何其他的包(Ce = 0)。它是负有责任且无依赖性的。这种包达到了大程度的稳定性。它的依赖者使其难以更改,而且没有任何依赖关系会迫使它去改变
5.7. Stable Abstractions Principle (SAP) 稳定抽象原则
- 稳定的包应该是抽象的包(接口) stable packages should be abstract packages
- 不稳定的包应该是具体的包 unstable packages should be concrete packages
- 稳定的包装包含高层的设计。
- 使它们成为抽象可以对拓展开放,对修改关闭(OCP开闭原则)
- 稳定的难以更改的包装中保留了一些灵活性。
5.7.1. 抽象性度量
- 包的抽象性用抽象类的数⽬和包中所有类的数目进行计算。
- 假如说包中类的总数是Nc, 抽象类的数⽬是Na,那么抽象度A = Na / Nc
- 距离这条斜线越近,合理性越高

- String类(Instability、Abstraction原点)
- String类就是尴尬的处于原点的一个包,很稳定,大家都依赖String,但不抽象,导致任何对String的修改都有可能导致之前开发的java程序无法运行。
5.7.2. 例子
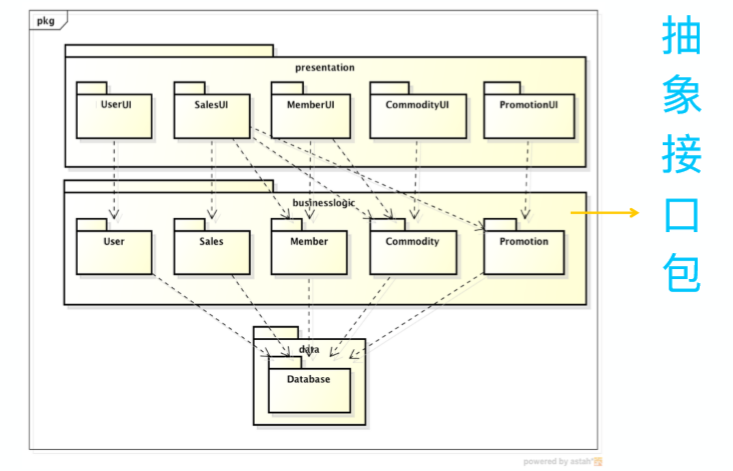
使用一个接口,展示层调用,逻辑层实现;使用一个接口,逻辑层调用,数据层实现【类比 spring MVC 中就是如此,层与层之间使用接口】是合理的:抽象的是稳定的,具体的是不稳定的。
如上面图中的则不合适
5.8. 包设计的过程
- 迭代的过程:先用 CCP 原则对把可能⼀同变化的类组织成包进⾏发布
- 随着系统的不断增⻓,我们开始关注创建可重用的元素,于是开始使⽤ CRP 和 REP 来指导包的组合。
- 后使⽤ ADP、SDP、SAP 对包图进⾏度量,去掉不好的依赖。(修改设计)
6. 第四步:依赖逻辑设计进行软件体系结构(实现)设计;
逻辑视角描述的是一个概念上的抽象的系统,并不是一个实实在在的物理上的系统 以,需要将软件体系结构的逻辑设计从开发(开发包、物理模块)、发布(进程)、部署(网络 部署)三个角度进行实现,建立软件体系结构的物理设计。
- 开发包(构件)设计
- 运⾏时的进程
- 物理部署
6.1. 初始物理包
简单的情况下,逻辑设计中每一个包都可以转化为一个开发包

6.2. 细节考虑(重要)

- Presentation 层与 Logic 层被置于客户端,Data 层被置于服务器端,那么 Logic 层的开发包依赖于 Data 层的开发包是不可能的。
- 可以考虑使⽤ RMI 技术,RMI 技术会将 Data 层开发包分解为置于客户端的 dataservice 接口包和置于服务器的 data 开发包。这样⼀来,Logic 层开发包依赖于 dataservice 包,dataservice 和 data 层的开发包都依赖于 RMI 类库包。
- 所有的 Data 层开发包都需要进⾏数据持久化(例如读写数据库、读写⽂件等),所以它们会有⼀些重复代码,可以将重复代码独⽴为新的开发包然后所有的 Data 层开 发包都依赖于 databaseutility,databaseutility 会依赖于 JDBC 类库包或者 IO 类库包。

- 所有的 Presentation 层开发包都需要使用图形类型建立界面,都要依赖于图形界面类库包。
- 此外,Presentation 层实现时,由 mainui 包负责整个页面之间的跳转逻辑。其它各包负责各自页面自身的功能。

- 在分层风格的典型设计中,不希望高层直接依赖于低层,⽽是为低层建⽴接⼝包, 实现依赖倒置原则[程序要依赖于抽象接口,不要依赖于具体实现](参⻅ 15.4.4), 所以应该调整为:各 Prensentatin 层开发包(调⽤)依赖于 Logic 层接⼝包 businesslogicalservice 包,Logic 层开发包(实现)依赖于 Logic 层接⼝包 businesslogicalservice 包。
- 在分层⻛格的典型设计中,Presentation 层与 Logic 层之间、Logic 层与 Data 层之间可能会传递复杂数据对象,那么相邻两层都需要使⽤数据对象声明,所以需要将数据对象声明单独独⽴为开发包**(VO 包与 PO 包)**,或者将数据对象声明放⼊接⼝包(VO 包放⼊ Logic 接⼝包,PO 包独⽴)。
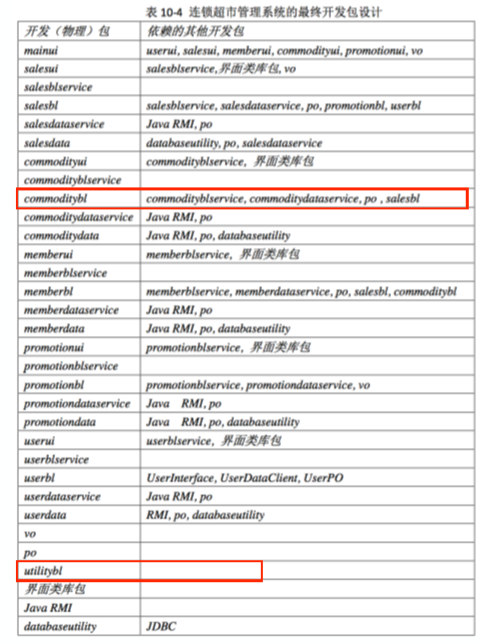
- 开发包的循环依赖现象需要消除,对此可以使⽤依赖倒置原则将循环依赖变为单向依赖: 【即消除依赖循环的第二种情况】
- Sales与Commodity:将部分 Commodity类抽象接口 commodityInfoService置⼊ Sales 包, 这样 Commodity 单向依赖于 Sales(实现接⼝+调⽤)。
- Sales 与 Member:将部分 Member 类抽象接⼝置⼊ Sales 包,这样 Member 单向依赖于 Sales(实现接⼝+调⽤)。
- 在 Logic 层中,⼀些关于初始化和业务逻辑层上下文的工作被分配到 utilitybl 包中去。
补充:4+1 view



6.3. 连锁超市管理系统开发包图
- 客户端

- 服务器端

6.4. 进程图
- 进程图主要是表明运行时的进程,以及个进程间如何进行通信的。

6.5. 部署图
- UML部署图描述了一个运行时的物理节点,以及在这个节点上运行的软件构建的静态视图。

7. 第五步:完善体系结构设计
- 完善软件体系结构设计
- 细化软件体系结构设计
7.1. 增加启动模块和网络模块(完善)
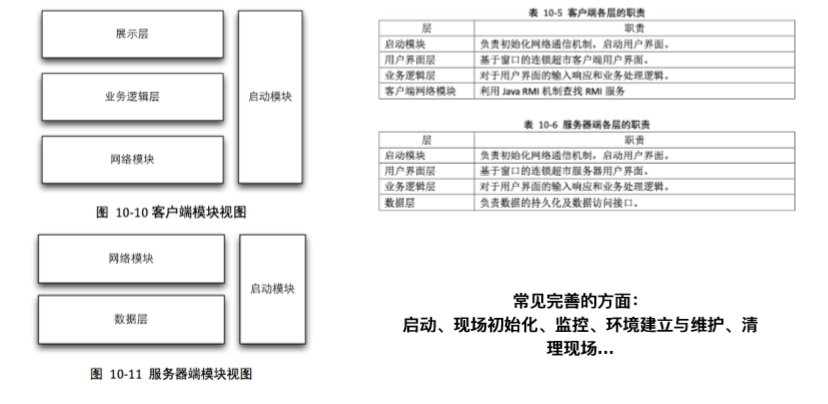
- 失败业务的现场保护问题
- 网络连接断开的恢复问题
- 除了细化职责建立关键类图之后,模块传递的数据对象也需要被明确定义,因为他们是模块间接口的重要部分,必须严格、准确。
7.2. 细化salesbl模块
软件体系结构设计方案如果仅仅停留在模块的层次,不利于验证其正确性。可以适当进行软件体系结构的细化,建立能够承载模块职责的关键类。关键类建立的过程中往往能够发现软件体系结构设计时忽略的细节。

7.3. 细化数据定义
- 接口的数据对象
- 关键类的重要数据结构
- Value Object (VO)
- Persistent Object(PO)
- ⽤POJO实现
7.3.1. Java 实体
- 实体是一个可以代表一个临时的业务实体的对象,比如一个账单或者用户
- 只是用来保存数据
- 没有逻辑业务方法(行为)
- 实体必须在使用它们的会话或事务之间持久存在。
- 实体是存储在文件或者数据库中的
- 实体是一个Beans,如VO,PO等都是实体类
- Simple or EJB.
JavaBean
JavaBean是公共Java类,但是为了编辑工具识别,需要满足至少三个条件:
- 有一个public默认构造器(例如无参构造器,)
- 属性使用public 的get,set方法访问,也就是说设置成private,同时get,set方法与属性名的大小也需要对应。例如属性name,get方法就要写成,public String getName(){},N大写。
- 需要序列化。这个是框架,工具跨平台反映状态必须的
Because these requirements are largely expressed as conventions rather than by implementing interfaces, some developers view JavaBeans as Plain Old Java Objects that follow specific naming conventions.
最近看
,里面讲到JavaBean最初是为Java GUI的可视化编程实现的.你拖动IDE构建工具创建一个GUI 组件(如多选框),其实是工具给你创建java类,并提供将类的属性暴露出来给你修改调整,将事件监听器暴露出来.《java 编程思想(第四版)》p823-824 EJB
在企业开发中,需要可伸缩的性能和事务、安全机制,这样能保证企业系统平滑发展,而不是发展到一种规模重新更换一套软件系统。 然后有提高了协议要求,就出现了Enterprise Bean。
EJB在javabean基础上又提了一些要求,当然更复杂了。
POJO
有个叫Josh MacKenzie人觉得,EJB太复杂了,完全没必要每次都用,所以发明了个POJO,POJO是普通的javabean,什么是普通,就是和EJB对应的。该名称用于强调所讨论的对象是普通 Java 对象,而不是特殊对象,尤其不是 Enterprise JavaBean
总之,区别就是,你先判断是否满足javabean的条件,然后如果再实现一些要求,满足EJB条件就是EJB,否则就是POJO【如果满足javaBean就是javaBean,否则就是POJO,当然javaBean也是POJO】。
A JavaBean is a POJO that is serializable, has a no-argument constructor, and allows access to properties using getter and setter methods. An Enterprise JavaBean is not a single class but an entire component model : JavaBean 是可序列化的 POJO,具有无参数构造函数,并允许使用 getter 和 setter 方法访问属性。 Enterprise JavaBean 不是一个单一的类,而是一个完整的组件模型
7.3.2. POJO(Plain Old Java Objects)= Simple Java Entities
1 | public class Person extends Entity { |
7.3.3. Value Objects(逻辑层向展示层传递数据)
A Value Object or VO is an object such as java.lang.Integer that hold values (hence value objects).
对于很多人来说,DTO 和 VO 是一回事(但 Fowler 使用 VO 来表示我们看到的其他东西)。 大多数时候,它们遵循 JavaBeans 约定,因此也是 JavaBeans。 而且都是 POJO。
- 价值对象(VO)包含一个或多个公共领域中实体的属性。
- 在层之间传递值对象,而不是实体。
- 应该考虑实现Serializable
- 值对象可以更新和创建实体。
- 实体可以创建价值对象。
1 | public class PersonVO extends ValueObject { |
7.3.4. 图书地址业务实体

- 可以是多个实体的集合
7.4. 项目实践
- VO: View层与Logic之间的数据传递
- Customer(VIP)VO、CommodityVO、SaleLineItemVO、PaymentVO、 GiftVO…
- PO:Logic与Data层之间的数据传递
- SalesPO、SaleLineItemPO、CustomerPO、CommodityPO、 PaymentPO、GiftPO…
7.5. 持久化对象 UserPO的细化
1 | public class UserPO implements Serializable { |
8. 第六步:添加构件接口
8.1. 构件初步设计
- 根据分配的需求确定模块对外接⼝
- 初步设计关键类
- 编写接口规范
8.2. 确定模块对外接口
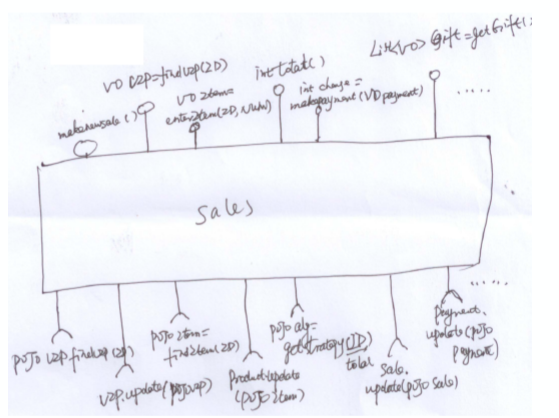
- 有的接口是面向业务的
8.3. 编写接口规范
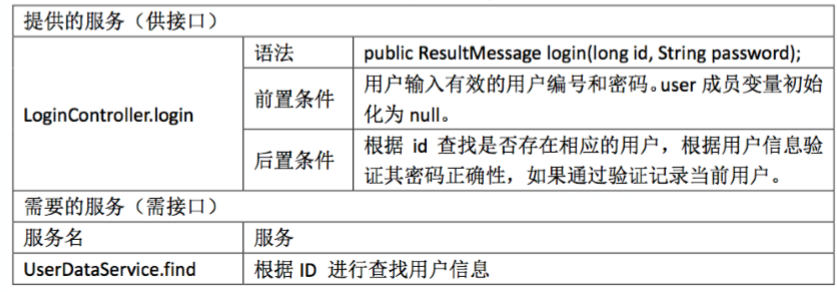
- 规范的书写
8.4. 接口怎么定(必考根据需求写接口)
-
接口来源于哪?
-
逻辑层接口来源于需求,根据需求规格文档/刺激响应序列可以确定展示层要调用逻辑层什么内容。刺激是接口的输入参数,响应是接口的返回值
-
数据层接口来源于逻辑层代码,增删改查,需要什么就提供什么。不需要的就不提供(如红冲,就是不能删除,那么接口里面就不需要提供删除)
【当然有可能业务层和逻辑层一样,即比如会员管理,业务层就只是有增删改查的业务,数据层也是这样,一个业务方法对应一个数据方法,这是简单的情况,在复杂情况时是一个业务方法使用多个数据方法】
-
9. 体系结构的原型构建(以上均为设计)
9.1. 包的创建
- 包用于将系统组织成有层次结构的机制,可以根据构件的设计来创建项目的包。
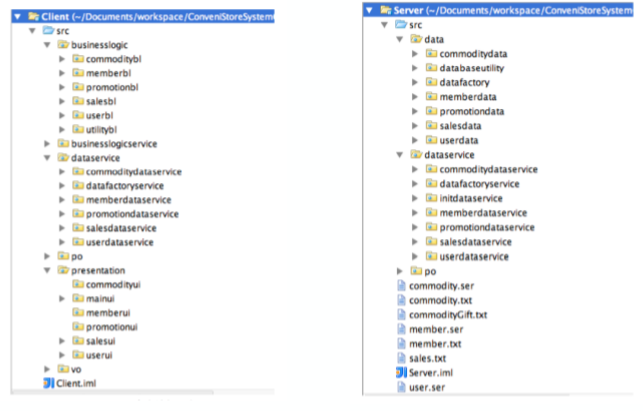
9.2. 重要文件的创建
- 可选
- 数据文件
- 系统文件
- 配置文件
9.2.1. 文件列表
- SalesBLService的定义
1 | public interface SalesBLService { |
9.3. 定义构件之间的接口
- 在包和文件定义之后,我们可以着力开始定义构件之间的接口
9.4. 关键需求的实现
- 实现一些关键 功能需求。
- ⽐如连锁超市系统中销售用例就是⼀个关键的用例。它所覆盖的面广,如果销售用例可以实现的话,其它⽤例的实现就⽐较有信⼼了。⽽且这个需求需要做到端到端的实现。
- ⽐如,连锁超市系统中存在客户端和服务器端。那么我们就需要在客户端通过 GUI 界⾯发出指令,通过客户端的业务逻辑处理,访问服务器端的数据,对数据进行修改。只有这样才能表明当前的体系结构可以胜任功能性需求。
- 对原型的非功能性指标进⾏估算和验证。如果出现不符合非功能性需求和项目约束的情况,我们还需要重新对体系结构设计进⾏调整。
- ⽐如,连锁超市系统中我们⽤文件来保存数据,⽽当数据越来越多,特别是销售记录要保存 1 年。这时候,客户端跨⽹络对服务器上⽂件的查找就⽐较慢,可能会使得我们不满⾜实时性的要求。
- 这时候,可能我们就要调整体系结构中数据存储的⽅案,⽐如换成数据库。或者在客户端的逻辑层和数据层之间,加设数据映射层。在客户端运⾏初始化时,将数据从服务器端载⼊到客户端的内存中去。
10. 体系结构集成与测试
10.1. 集成的策略
- 当体系结构中原型各个模块的代码都编写完成并经过单元测试之后,需要将所有模块组合起来形成整个软件原型系统, 这就是集成。
- 集成的目的是为了逐步让各个模块合成为⼀个系统来⼯作,从而验证整个系统的功能、性能、可靠性等需求。
- ==对于被集成起来的系统⼀般 主要是通过其暴露出来的接⼝,伪装⼀定的参数和输⼊,进⾏黑盒测试。==
- 根据从模块之间集成的先后顺序,⼀般有下列⼏种常⻅的集成策略:
- 大爆炸式(所有放在一起,看能不能过)
- 增量式
- 自顶向下式
- 自底向上式
- 三明治式(既自顶向下,又自底向上,既要写stub,也要写driver)
- 持续集成
- 模块开发完成后我们进行开发集成测试用例
10.1.1. 大爆炸集成
- 大爆炸集成:将所有模块一次性组合在一起。
- 优点:可以在短时间内迅速完成集成
- 缺点:一次运行成功可能性不高,不容易发现bug
10.1.2. 自顶向下集成
- 自顶向下集成是对分层次的架构,先集成和测试上层的测模块,下层的模块用伪装的具体接口的桩程序。
- 自顶向下集成的优点:
- 按深度优先可以⾸先实现和验证⼀个完整的功能需求;
- 只需顶端⼀个驱动(Driver);
- 利于故障定位。
- 一般会带来比较好的顶层设计的优势。
- 自顶向下集成的缺点:
- stub桩的开发量大;
- 底层验证被推迟,且底层组件测试不充分。
- 自顶向下基层适用于控制结构比较清晰和稳定、高层接口变化较小、底层接口未定义或经常被修改、控制组件有具有较大的技术风险的软件系统。

- 测试M1的时候,我们使用假的S7,S4来进行代替**(简单的代替这个模块)(被叫做Stub桩)**
10.1.3. 自底向上集成

- 高层设计的错误不会被很快的发现。而这往往被我们认为会带来比较致命的问题
- 优点:
- 对底层组件较早进行验证
- 底层组件开发可以并行
- 桩的工作量少
- 缺点:
- 驱动的开发作用量大
- 对高层的设计被推迟,设计上的高层错误并不能被及时发现
10.1.4. 持续集成
- 一种增量集成⽅法,但它提倡尽早集成和频繁集成。
- 尽早集成是指不需要总是等待⼀个模块开发完成才把它集成起来,⽽是在开发之初就利⽤ Stub 集成起来。
- 频繁集成是指开发者每次完成⼀些开发任务之后,就可以⽤开发结果替换 Stub 中的相应组件,进⾏集成与测试。⼀般来说,每⼈每天⾄少集成⼀次,也可以多次。
- 结合尽早集成和频繁集成的办法,持续集成可以做到:
- 防⽌软件开发中出现无法集成与发布的情况。因为软件项⽬在任何时刻都是可以集成和发布的。
- 有利于检查和发现集成缺陷。因为早的版本主要集成了简单的 Stub,⽐较容易做到没有错误。后续代码逐渐开发完成后,频繁集成⼜使得即使出现集成问题也能够尽快发现、尽快解决。
- 持续集成的频率很⾼,所以手动的集成对软件⼯程师来说是⽆法接受的,必须利⽤版本控制⼯具和持续集成⼯具。如果程序员可以仅仅使⽤⼀条命令就完成⼀次完整的集成,开发团队才有动⼒并且能够坚持进⾏频繁的集成。
- 工具:Jenkins,maven,gitlab等
- 如果你们的团队选择,白天进行代码开发,晚上进行代码测试,如果晚上你的代码出现比较严重的问题的时候,有可能会叫醒你来修改代码,以避免第二天浪费更多的时间。
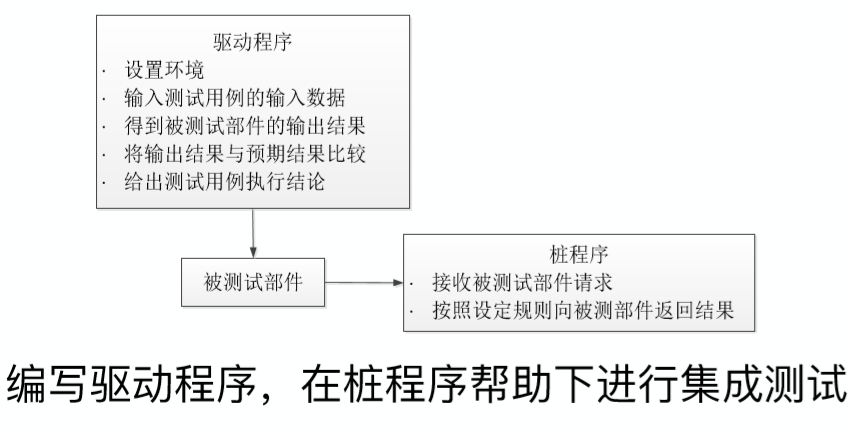
10.2. 依据模块接口建立桩程序Stub
- Stub 桩程序
- 为了完成程序的编译和连接⽽使⽤的暂时代码
- 对外模拟和代替承担模块接⼝的关键类
- ⽐真实程序简单的多,使⽤为简单的逻辑:比如简单的替代DAO层。

**Stub:**用于测试上层,如用于测试上层可以写简单的DAO层,不需要与数据库交互,直接返回我们设定好的数据

**Driver:**用于测试下层,比如用于测试DAO层时,我们会编写一些service和control,仅仅用于测试这个DAO是不是正确

10.3. 集成与构建
- 集成
- 使⽤桩程序辅助集成
- 编译与链接
- 持续集成
- 逐步编写各个模块内部程序,替换相应的桩程序【在桩被替换后不一定要立刻删掉,可以注释保留】
- 真实程序不仅实现业务逻辑,⽽且会使⽤其他模块的接⼝程序(真实程序或者桩程序)
- 每次替换之后都进⾏集成与测试
10.4. 项目实践
- 客户端
- View层:HCI特殊测试,需要模拟logic的stub
- Logical层:
- 驱动模拟来⾃View层的请求
- 桩程序模拟远程Data
- 需要模拟同层调用的driver和stub
- 服务器端(Data层)
- 驱动模拟来⾃客户端的请求
- 桩程序模拟未完成的Data模块接⼝
11. 体系结构文档化
11.1. 体系结构设计文档模版 IEEE1471-2000

12. 体系结构评审
12.1. 评审的角度
- 设计⽅案正确性、先进性、可行性;
- 系统组成、系统要求及接⼝协调的合理性;
- 对于功能模块的输⼊参数、输出参数的定义是否明确;
- 系统性能、可靠性、安全性要求是否合理;
- ⽂档的描述是否清晰、明确。
12.2. 体系结构评审的方法
- 对结果的评审:Checklist(动态更新的)
- 对设计决策的评审:如果无法对结果进行评审,那么就对原因进行评审,如果产出这个东西的原因是合理的,那么结果就认为是合理的
12.3. 软件体系结构设计文档的Checklist
- 体系结构设计是否为后续开发提供了⼀个足够的视角?
- 是否所有的功能都被分配给了具体模块?
- 是否所有的⾮功能属性都得到了满⾜?
- 是否所有的项⽬约束都得到了满⾜?
- 体系结构设计是否为后继设计提供了简洁的概述、背景信息、限制条件和清晰的组织结构?
- 体系结构设计是否能应对可能发⽣的变更? [比如为了10万用户的设计体系结构设计能够实际支持20万的用户量]
- 体系结构设计是否关注点在详细设计和⽤户接⼝的层次之上?
- 不同的体系结构设计视⻆的依赖是否⼀致? [当系统比较复杂时,容易忽略]
- 系统环境是否定义,包括硬件、软件、和外部系统?