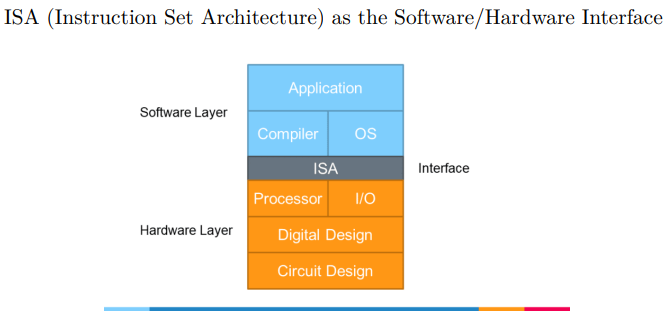
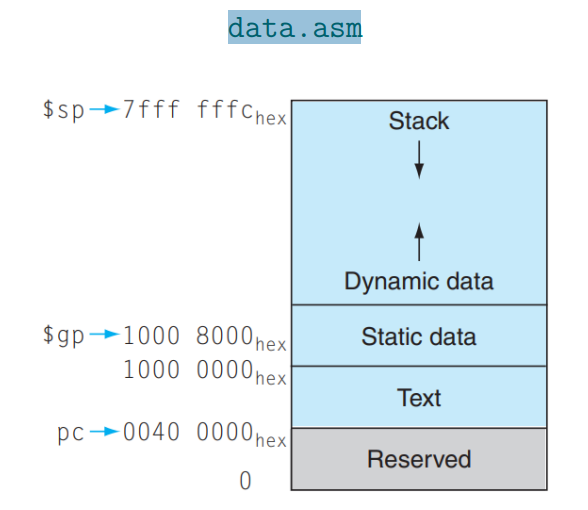
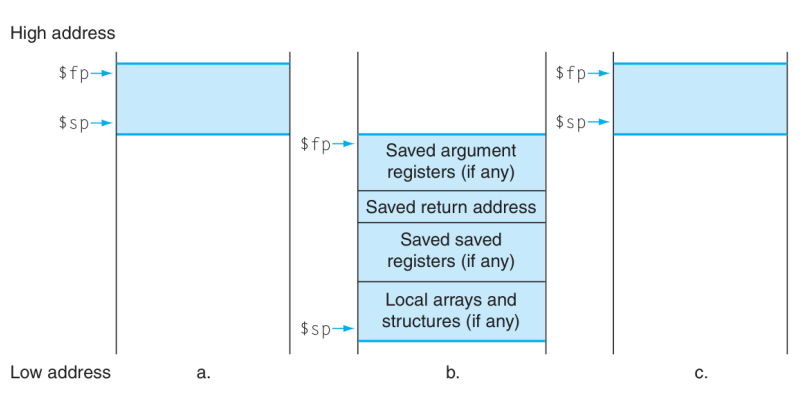
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
| square:
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], edi
mov eax, DWORD PTR [rbp-4]
imul eax, eax
pop rbp
ret
numbers:
.long 20
.long 3
.long 56
.long 8
.long 90
size:
.long 5
main:
push rbp
mov rbp, rsp
mov eax, DWORD PTR size[rip]
mov esi, eax
mov edi, OFFSET FLAT:numbers
call Sort
mov eax, 0
pop rbp
ret
Sort:
push rbp
mov rbp, rsp
sub rsp, 32
mov QWORD PTR [rbp-24], rdi
mov DWORD PTR [rbp-28], esi
mov DWORD PTR [rbp-4], 0
jmp .L6
.L10:
mov eax, DWORD PTR [rbp-4]
sub eax, 1
mov DWORD PTR [rbp-8], eax
jmp .L7
.L9:
mov edx, DWORD PTR [rbp-8]
mov rax, QWORD PTR [rbp-24]
mov esi, edx
mov rdi, rax
call Swap
sub DWORD PTR [rbp-8], 1
.L7:
cmp DWORD PTR [rbp-8], 0
js .L8
mov eax, DWORD PTR [rbp-8]
cdqe
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov edx, DWORD PTR [rax]
mov eax, DWORD PTR [rbp-8]
cdqe
add rax, 1
lea rcx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rcx
mov eax, DWORD PTR [rax]
cmp edx, eax
jg .L9
.L8:
add DWORD PTR [rbp-4], 1
.L6:
mov eax, DWORD PTR [rbp-4]
cmp eax, DWORD PTR [rbp-28]
jl .L10
nop
nop
leave
ret
Swap:
push rbp
mov rbp, rsp
mov QWORD PTR [rbp-24], rdi
mov DWORD PTR [rbp-28], esi
mov eax, DWORD PTR [rbp-28]
cdqe
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov eax, DWORD PTR [rax]
mov DWORD PTR [rbp-4], eax
mov eax, DWORD PTR [rbp-28]
cdqe
add rax, 1
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov edx, DWORD PTR [rbp-28]
movsx rdx, edx
lea rcx, [0+rdx*4]
mov rdx, QWORD PTR [rbp-24]
add rdx, rcx
mov eax, DWORD PTR [rax]
mov DWORD PTR [rdx], eax
mov eax, DWORD PTR [rbp-28]
cdqe
add rax, 1
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rdx, rax
mov eax, DWORD PTR [rbp-4]
mov DWORD PTR [rdx], eax
nop
pop rbp
ret
.LC0:
.string "%d\n"
Print:
push rbp
mov rbp, rsp
sub rsp, 32
mov QWORD PTR [rbp-24], rdi
mov DWORD PTR [rbp-28], esi
mov DWORD PTR [rbp-4], 0
jmp .L13
.L14:
mov eax, DWORD PTR [rbp-4]
cdqe
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov eax, DWORD PTR [rax]
mov esi, eax
mov edi, OFFSET FLAT:.LC0
mov eax, 0
call printf
add DWORD PTR [rbp-4], 1
.L13:
mov eax, DWORD PTR [rbp-4]
cmp eax, DWORD PTR [rbp-28]
jl .L14
nop
nop
leave
ret
|