ch05-Spring Data JDBC、JPA
代码仓库:https://github.com/tzs919/taco-cloud-05
使用JdbcTemplate简化JDBC访问(spring-boot-starter-jdbc)
使用原始的JDBC访问数据库
- RawJdbcIngredientRepository
- 样板式代码(ResultSet、PreparedStatement、Connection)
- SQLException,checked异常
异常体系
- SQLException
- 发生异常时很难恢复
- 难确定异常类型
- Hibernate异常
- 定义了许多具体异常,方便定位问题
- 对业务对象的侵入
- Spring所提供的平台无关的持久化异常
- DataAccessException
- 具体异常,方便定位问题
- 隔离具体数据库平台
使用JdbcTemplate
添加依赖
1 | <dependency> |
创建数据库
需要在根路径下提供schema.sql
springboot会自动帮助实例化数据库,创建表
1 | create table if not exists Taco_Order ( |
data.sql
紧接着会执行该文件,初始化数据库
1 | delete from Ingredient_Ref; |
提供用户名和密码
application.yml
1 | #tag::setDatabaseName[] |
数据库表
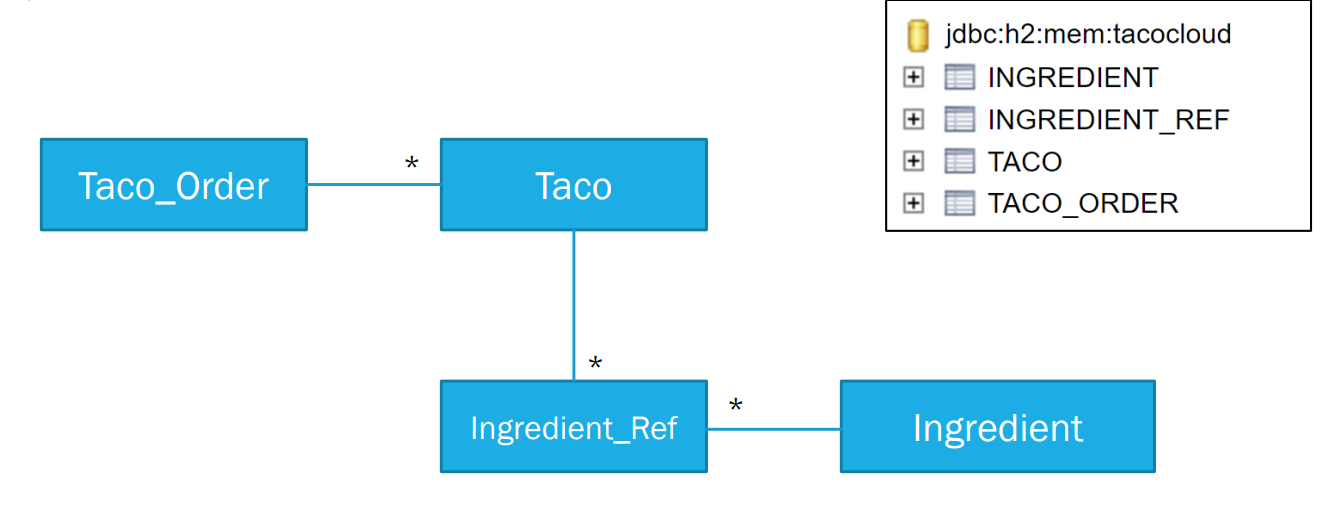
业务层访问dao层所需要经历的接口
IngredientRepository
1 | package tacos.data; |
spring框架下的实现
IngredientRepository的实现
- 注入JdbcTemplate,如果只有一个构造方法可以省去@Autowired
- @Repository
- 接口:RowMapper,可以使用lambda表达式
- 注入DesignTacoController,使用
- IngredientByIdConverter实现优化
JdbcIngredientRepository
- @Repository:帮助spring发现这个类,并将其实例化到上下文中
1 | package tacos.data; |
JdbcOrderRepository核心代码
save(TacoOrder order)的实现
- Taco不能脱离TacoOrder而存在,聚合关系
- JdbcOrderRepository
- identity字段由数据库自动生成值,获取返回的ID,GeneratedKeyHolder
- PreparedStatementCreatorFactory
- PreparedStatementCreator
- jdbcOperations.update
- 注入OrderController,使用
1 | package tacos.data; |
JDBC的方式:RawJdbcIngredientRepository
核心、模板化的、最原始的
1 | package tacos.data; |
业务层实现
controller
DesignTacoController
1 | package tacos.web; |
OrderController
1 | package tacos.web; |
附带tacoOrder类
1 | package tacos; |
附带taco类
1 | package tacos; |
IngredientRef:用配料的id唯一标识引用一个配料
1 | package tacos; |
转化客户端的字符串为ingredient的对象
IngredientByIdConverter
控制器层无需知道repo的具体实现,只需要知道接口就好
@Component && @Autowired:自动注入的方式
1 | package tacos.web; |
H2访问
- http://localhost:8080/h2-console
- 驱动:org.h2.Driver
- JDBC URL:jdbc:h2:mem:tacocloud
- 用户名:sa
Spring Data项目
属于Spring Data项目,和上面的JDBC不一样。进一步简化,只需要提供接口。
异同
- 异
- 只定义了一个接口
CrudRepository
- 同
- 需要自己创建表(scheme.sql脚本定义表结构),data.sql初始化数据
- Spring Data JDBC
- Spring Data JPA
- Spring Data MongoDB
- Spring Data Neo4j
- Spring Data Redis
- Spring Data Cassandr
Spring Data JDBC
添加依赖
1 | <dependency> |
步骤
- 添加依赖
- 定义存储库接口
- 为领域类添加持久化注解
存储库接口
- Spring Data会在运行时自动生成存储库接口的实现。但是,只有当接口扩展自Spring Data提供的存储库接口时,它才会帮我们实现这一点。
- Repository接口是参数化的,其中第一个参数是该存储库要持久化的对象类型;第二个参数是要持久化对象的ID字段的类型。
1 | public interface IngredientRepository extends Repository<Ingredient, String> { |
1 | public interface IngredientRepository extends CrudRepository<Ingredient, String> { |
CrudRepository接口包含了增删改查等基础操作
当应用启动的时候,Spring Data会在运行时自动生成一个实现。这意味着存储库已经准备就绪,我们将其注入控制器就可以了。
实现
详细解释不同之处:只需要一个接口不需要实现,拓展自CrudRepository
IngredientRepository
1 | package tacos.data; |
crud:增删改查
这样写spring会自动实现增删改查
需要额外告诉spring一些信息:java对象与数据库中的表的对应关系,如果名字一样可以省略注解
Ingredient
1 | package tacos; |
OrderRepository
1 | package tacos.data; |
为领域类添加持久化的注解
- @Table,对象会基于领域类的名称映射到数据库的表上
- TacoOrder会映射到Taco_Order表
- @Id
- @Column
- deliveryName会映射到delivery_Name列
程序预加载
- org.springframework.boot.CommandLineRunner
- org.springframework.boot.ApplicationRunner
TacoCloudApplication
1 | package tacos; |
Spring Data JPA
- JPA:Java Persistence API
- JPA的宗旨是为POJO提供持久化标准规范
- JPQL是一种面向对象的查询语言
- 依赖
1 | <dependency> |
实现
- 添加依赖
- 定义接口:接口跟spring data jdbc一致,业务层和控制器层无需修改
- 在实体类中指定对应关系,打上**@Entity**,见Ingredient, scheme.sql不用手写,根据java对象的定义自动生成表结构
- id属性需要使用@Id注解,以便于将其指定为数据库中唯一标识该实体的属性
@GeneratedValue(strategy = GenerationType.AUTO)- 依赖数据库自动生成ID值
1 | package tacos; |
taco
@ManyToMany():多对多,表与taco多对多
1 | package tacos; |
tacoOrder
@OneToMany(cascade = CascadeType.ALL)一对多
all是级联,tacoOrder不存在,taco也不存在
1 | package tacos; |
自定义JPA存储库
DSL
- Spring Data定义了一组小型的领域特定语言(Domain-Specific Language,DSL),在这里,持久化的细节都是通过存储库方法的签名来描述的。
- 存储库的方法由一个动词、一个可选的主题(subject)、关键词By,以及一个断言组成。
- 常用动词:get、read、find、count
- 例子:
1 | List<TacoOrder> findByDeliveryZip(String deliveryZip); |
在findByDeliveryZip()这个样例中,动词是find,断言是DeliveryZip,主题并没有指定,暗含的主题是TacoOrder。
JPQL
-
@Query1
2
3
- 在查询语句中写SQL语句
@Query(“Order o where o.deliveryCity = ‘Seattle’”)
List
- 同样适用于Spring DataJDBC,但存在以下差异
1. 在@Query中声明的必须全部是**SQL查询**,不允许使用JPA查询
2. 所有的自定义方法都需要使用@Query。这是因为,与JPA不同,我们没有映射元数据帮助Spring Data JDBC根据方法名自动推断查询。
## 数据访问对象模拟
常用工具**Mockito**
- 业务层依赖接口
(依赖倒置)
- 接口实现可以替换不需要修改业务层
- 方便测试
## 三种方法区别、相同点👍
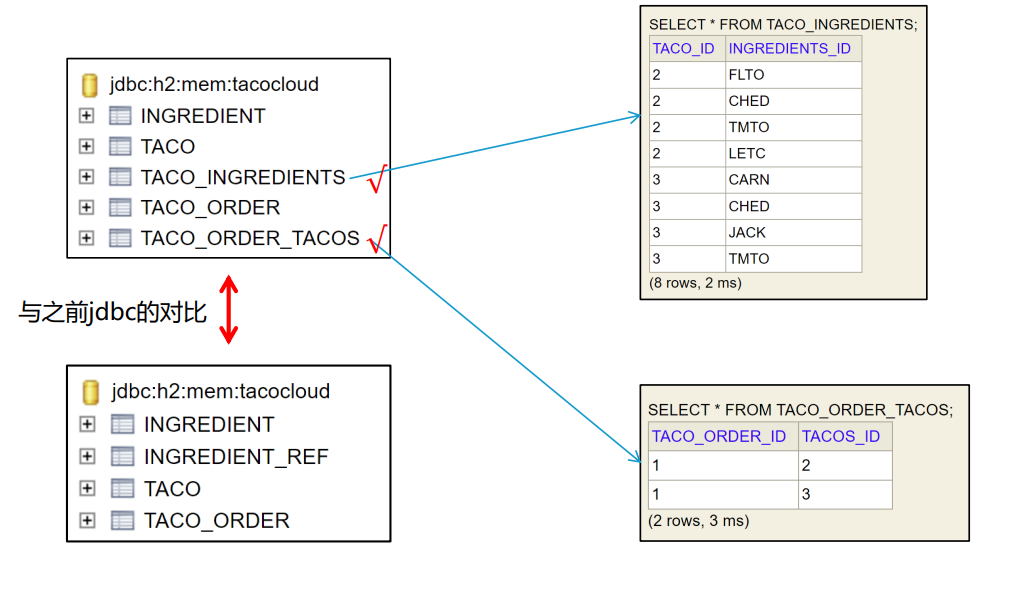
1. 数据表生成:1、2需要scheme脚本,3不需要(根据领域类自动生成)
2. 数据库访问层:1需要自己实现接口,2、3不需要
3. 领域类注解:1不需要为领域类加注解,2、3要为领域类加注解(提供领域类和表结构的映射关系)
- 2: @Id
- 3: @Entity, @Id
4. 自定义查询:2、3都可以使用@Querry定义查询逻辑,但3还可以使用基于方法名的DSL自定义查询
5. ID字段的处理:1需要手动获取数据库生成的Id,2、3不需要
6. 存储库接口:2、3都继承自CrudRepository接口
7. 包路径:2、3为领域类添加持久化的注解包路径不一样
- JPA中的规范注解都来自javax.persisitence.* ,因为不是Spring自己实现
- @Table,对象会基于领域类的名称映射到数据库的表上
- @Id
- 有两个来自不同包的@Id,主义区别
- @Column
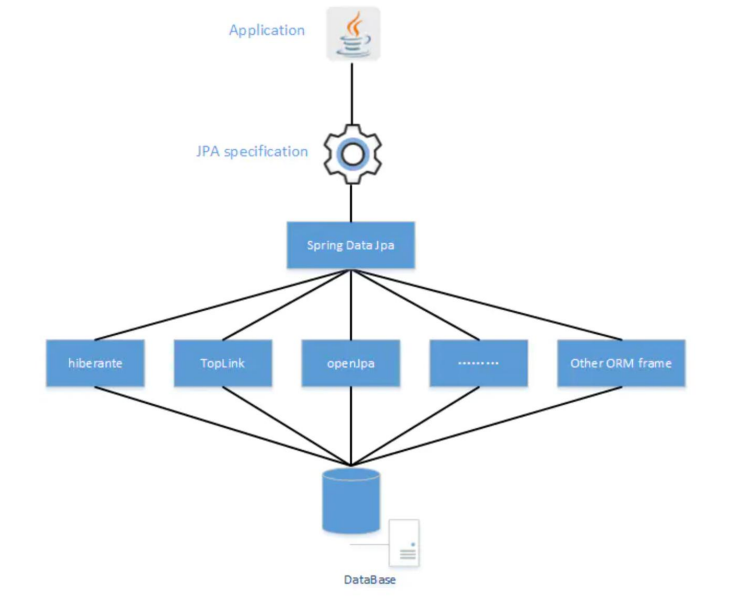
## Jpa、Hibernate、Spring Data Jpa三者之间的关系
## 自动生成的数据库表
## 定义的查询方法
* 定义查询方法,无需实现
* 领域特定语言(domain-specific language,DSL),spring data的命名约定
* 查询动词 + 主题 + 断言
* 查询动词:get、read、find、count
* 例子: List findByDeliveryZip( String deliveryZip );
* 声明自定义查询
* 不符合方法命名约定时,或者命名太长时
* @Query(“Order o where o.deliveryCity = 'Seattle'”) List readOrdersDeliveredInSeattle( );