自动化测试
测试的局限性
- 输入空间庞大 无法穷举所有输入
- 实现逻辑复杂 无法想到所有场景
- 测试预言未知 无法判定测试的预期输出
随机测试
大数定律
测试执行次数够多
测试数据随机生成
概率低的偶然现象发生
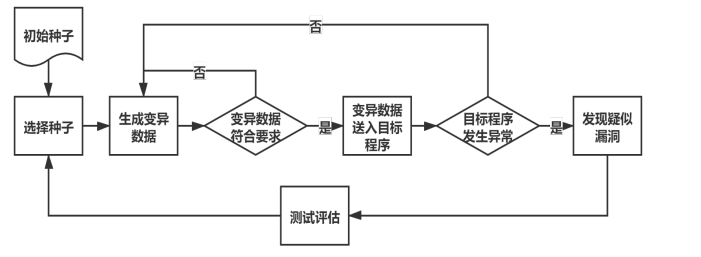
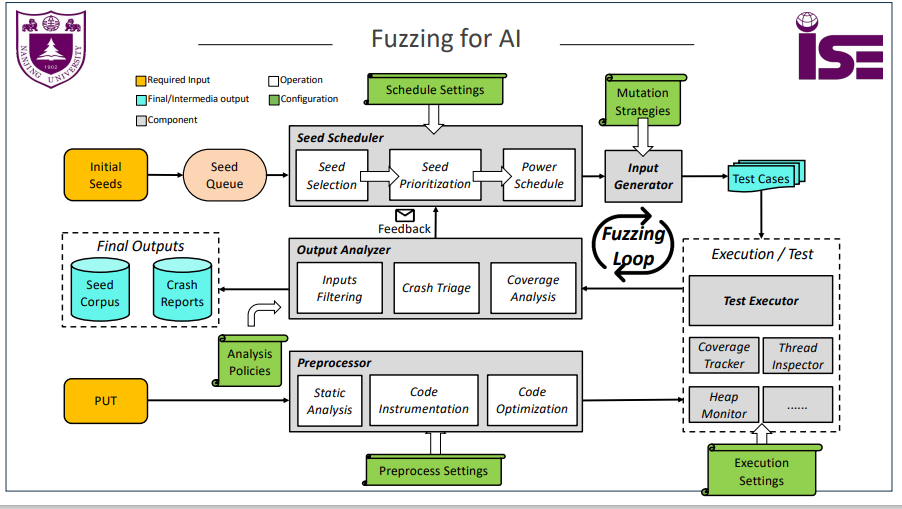
模糊测试
通过异常的输入自动化发现待 测程序缺陷的技术。
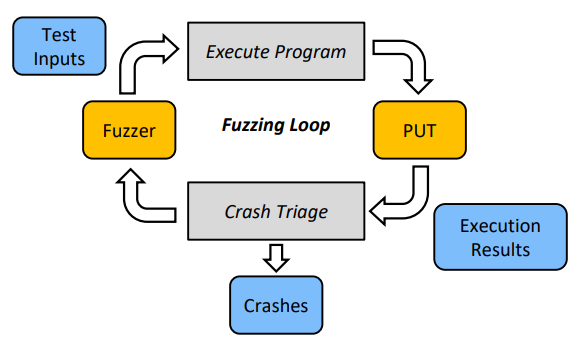
三个组件
输入生成组件(Input Generator)
测试执行组件 (Test Executor)
输出分析组件(Output Analyzer)
测试输入(Test Input)
测试输入是一组用于驱动待测程序执行的数据
测试用例(Test Case)
测试用例是一组用于确定应用软件或软件系统是否能够正确工作的条件或变量
输入 + 逻辑(调用序列) + 预言
种子输入(Seed Input)
种子输入是一个或一组在模糊测试过程中为输入生成(Input Generation)提供基准的测试输入,简称种子(Seed)。
框架
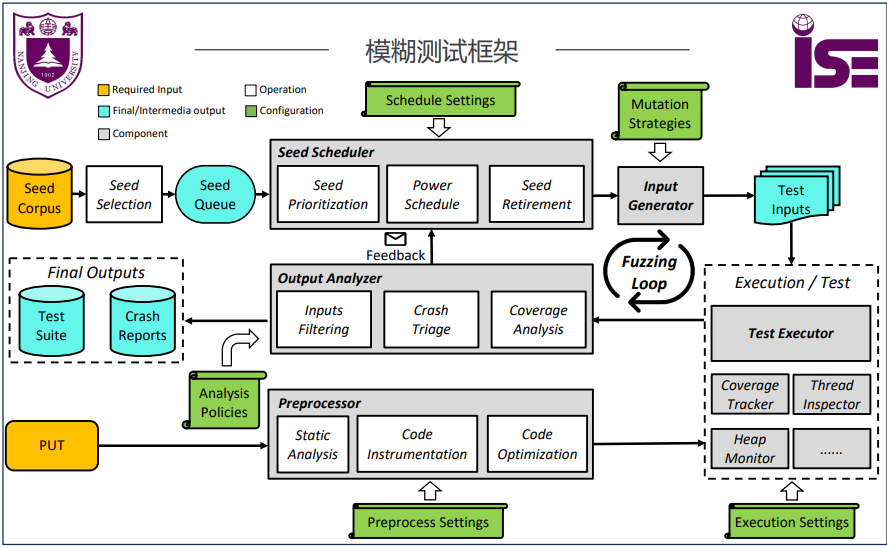
分类
根据组件核心或技术贡献进行分类
- 按照采用的运行时信息:黑盒、灰盒、白盒
- 按照输入生成的策略:Mutation-based, Generation-based
- 按照引导过程:Search-based(一些启发式算法),Gradient-based(梯度下降)
- 按照测试目标:定向、非定向、某一类缺陷
- 按照应用领域:网络协议、Compiler、DNN、IoT、内核
- 按照优化角度:种子调度、变异策略、能量调度、过程建模
黑盒(Blackbox)模糊测试
- 特点:不监控执行过程,也不使用执行过程中产生的任何信息, 仅从输入和输出端入手优化模糊测试
- 引导方式:利用输入格式或输出状态引导测试执行
- 优缺点:效率高,但引导的有效性上面有所欠缺
- 代表性工作:KIF 2 、IoTFuzzer 3 、CodeAlchemist 4
白盒(Whitebox)模糊测试
- 特点:使用混合执行、污点分析(Taint Analysis)等比较昂贵 的白盒分析技术优化模糊测试过程
- 引导方式:利用详细的程序分析结果引导测试执行
- 优缺点:反馈更加有效,但是效率不高、适配性较差
- 代表性工作:Driller2、QSYM3、CONFETTI4
灰盒(Greybox)模糊测试
- Coverage-based Greybox Fuzzing, CGF
- 特点:采用轻量级插装对程序进行监控,在执行过程中收集各类信息,如分支覆盖、线程执行、堆栈状态等
- 引导方式:利用收集到的执行信息(内部状态)引导测试执行
- 代表性工作:AFL、AFLGo、EcoFuzz、Zest、BeDivFuzz
基于变异的模糊测试
Mutation-based:基于随机变异或启发式变异策略
- 本质:将种子输入转换为比特串(Bits),对比特串进行变换
- 优点:可拓展性强,易于泛化,理论上可用于任意输入(图 片、文本、音视频)
- 缺点:容易破坏输入的结构、产生无效输入(Invalid Input);生成的大部分输入都无法通过语义检查 (Semantic Checking),很难探测深层次的程序状态和程序元素(Program Elements
AFL变异算子
- bitflip L/S :以S为增量,每次翻转L位
- arith L/8:加/减长度为L的小整数
- interest L/8:翻转“有趣”字节位
- havoc:对输入进行大肆破坏
- splice:随机拼接两个种子输入
基于生成的模糊测试
Generation-based:基于一定的文法规则/结构信息
- 本质:利用给定的、或者挖掘/学习得到的文法规则,来构建能够通过(语法)检查的结构化输入
- 优点:容易生成合法、有效输入(Valid Inputs),适用于对输入结构性要求较高的场景,如针对解析器(Parser)、解释器(Interpreter)以及编译器(Compiler)的测试
- 缺点:需要人工赋予一定的领域知识。在没有人工指定文法 的情况下,很难得到完整的文法规则
基于搜索的模糊测试
Search-based:Fuzzing as Search Problem
- 核心:将模糊测试过程建模为搜索问题,根据模型构造启发式算法(Heuristic)解决问题
- 启发式:遗传算法-AFL1、马尔科夫链-AFLFast2、信息熵Entropic3、多臂老虎机问题-EcoFuzz
基于梯度的模糊测试
Gradient-based:Fuzzing as Optimization Problem
- 核心:将模糊测试过程建模为优化问题,问题的目标是最大化缺陷发掘数量,利用梯度下降算法持续求解最优解
- 目标退阶:缺陷离散分布且无法预知 替换为代码覆盖 •
- 应用DL技术-Neuzz1 & MTFuzz2;利用梯度下降取代符号执行的约束求解过程-Angora3
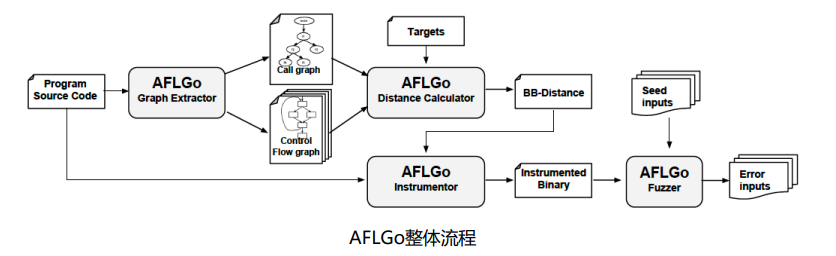
定向灰盒模糊测试
AFLGo1:定向灰盒模糊测试
基本思路:Distance + Annealing-based Scheduling,为 更靠近目标位置的种子分配更多的能量
变异测试
变异测试旨在找出有效的测试用例,发现程序中真正的错误。
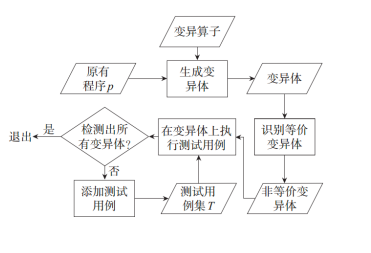
变异体
基于一定的语法(Syntax)变换规则,通过对源程序进行程 序变换(Program Transformation)得到的一系列变体
假设
- 源程序不包含缺陷 现有的测试套件没有发现缺陷
- 变异体表达了某种缺陷 人工缺陷(Artificial Defect)
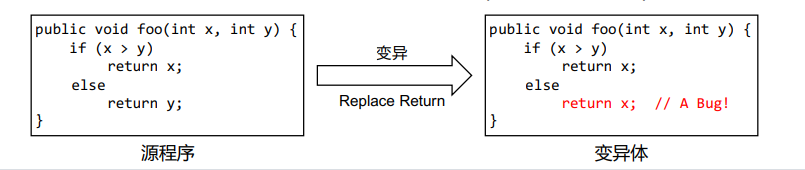
变异得分(Mutation Score)
-
变异测试对测试套件错误检测能力的量化
-
杀死与存活:变异体是否导致某个测试用例运行失败;测试 用例是否“检测”到某个变异体
- 检测到:变体被杀死(Killed)
- 未检测到:变体存活(Survived)
-
计算公式
$score = \frac{mut _k}{mut_s + mut_k}* 100%$
变异体的分类
- 有效变异体
- 夭折变异体(Stillborn Mutant)
- 等价变异体(Equivalent Mutant)
- 冗余变异体(Redundant Mutant)
- 重复变异体(Duplicated Mutant)
- 蕴含变异体(Subsumed Mutant)
等价
- 对于待测程序p的变体mut,如果mut和p的语法不同、语义相同,则称mut是p的等价变异体
- 语义相同:对于给定输入,两个程序总能给出相同的输出
蕴含
- 对于两个变体$mut_1$和$mut_2$,如果∀杀死$mut_1$的测试用例t都可以杀死$mut_2$,则称$mut_1$蕴含$mut_2$
变异算子(Mutation Operator)
- 一系列语法变换规则(Syntactic Transformation Rule)
- 变异(Mutate)的依据,反映了测试人员关注的缺陷种类
- 基本形式
- 对程序的源代码进行变换(Source Code Level)
- 对程序的编译结果(中间表示)进行变换,例如:针对Java Bytecode的程序变换算子
- 元变异(Meta-mutation)

变异测试为什么有效
- 假设1:缺陷是简单的、可模拟的
- 变异体能够模拟测试人员关注的缺陷类型,即:最常出现的 缺陷类型;
- 能够在变异测试中暴露这些人工缺陷的测试套件一定能检测出待测程序中潜在的同类缺陷
- 老练程序员假设:一个老练程序员编写的错误程序与正确程序相差不大
- 假设2:缺陷可叠加
- 复杂变异体可以通过耦合简单变异体得到
- 能够杀死简单变异体的测试用例可以杀死复杂变异体
- 假设3:缺陷检测有效性
- 缺陷检测能力是测试用例最重要的属性
- 变异得分能够有效地反映测试用例/套件的错误检测能力
- 传递性假设:能够杀死变异体(暴露人工缺陷)的测试用例 也能有效发现真实世界的缺陷
变异测试流程
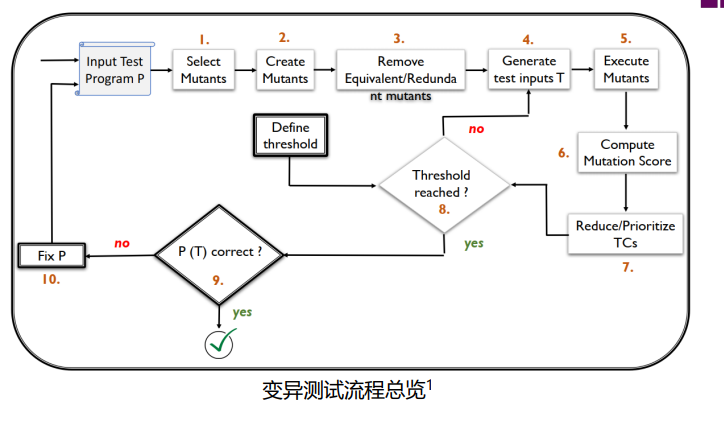
- 变异分析:1,2,3,5,6
- 变异应用:4,7,10
如何设计有效的变异算子?
设计原则
- 根据编程语言:Java,C#,C/C++,JS,AspectJ •
- 根据语言设计原则:OO,AOP
- 根据应用场景:Web,Android,Ajax
- 根据Bug类型:安全漏洞、内存缺陷、交互错误
变异体约减
变异体约减旨在从变异体全集中选出具有代表性变异体子集
约减策略
- 随机选取1:选取总量的10%~60%,缺陷丢失率为6%~26%
- 基于类型2:某些类型的变异体可能要更加重要
- 基于分布3:利用AST选取更加分散的变异体
变异体生成
变异体生成技术
- 元变异(Meta-mutation)
- 基于字节码操作(Bytecode Manipulation
- 热替换(Hot-Swap, Just-In-Time)
变异体优化
去除有等价和无效变异体
通过静态分析的方式,识别并移除有问题的变异
识别等价变异体
常用技术
- 代码优化(Code optimization)。对源代码和变异体进行优化, 移除优化后与源代码相同的变异体
- 静态数据流分析,如值分析(Value Analysis)。等价变异体汇 总存在特定的数据流模板,可以由此识别等价变异体
变异体执行
变异体矩阵
记录每个测试用例对每个变异体的执行情况
m*n维矩阵:m为变异体个数,n为测试用例个数
应用
- 评估作用:利用变异得分度量测试的充分性
- 引导作用:利用变异测试/分析的结果来引导测试过程
- 传统应用:应用于确定性系统
- 测试生成(Test Generation)
- 预言生成(Oracle Problem)
- 测试优化(排序 & 选择)
- Debug引导 (缺陷定位 & 自动修复
- 变异 & AI:应用于非确定性系统(DNN)
回归测试
回归测试研究框架
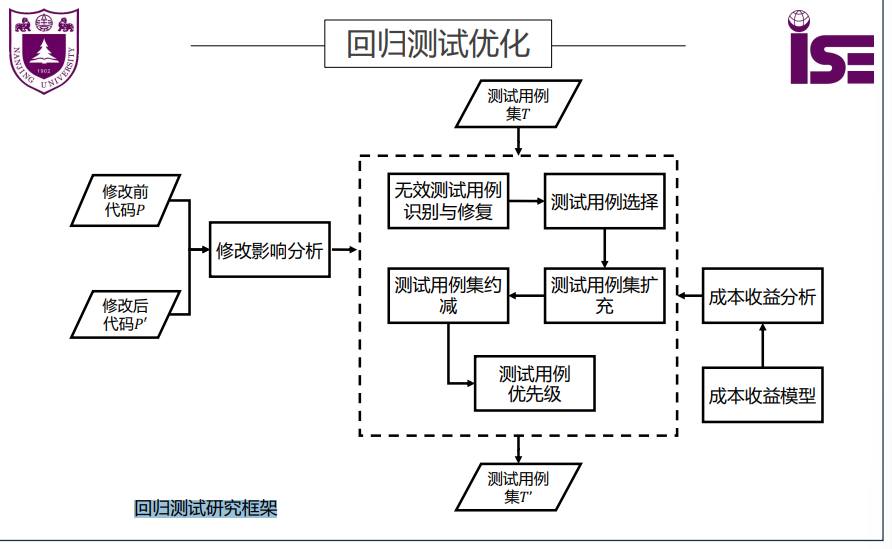
回归测试优化
-
测试用例修复 [1]:识别出因相关模块的外部接口或内在语义发生变更为失效的用例,并其进行修复。
-
测试用例选择 [2]:通过分析代码修改,从已有测试用例中选择出所 有可检测代码修改的测试用例,并确保未被选择的测试用例在修改前后程序上的执行行为保持一致。
-
测试用例扩充 [3] :在代码修改影响分析基础上,对已有测试用例集 的充分性进行评估,若不充分则设计新的测试用例以确保对代码修改的充分测试
-
测试用例缩减 [4]:在满足指定测试需求覆盖前提下,识别并移除冗 余测试用例来降低回归测试用例集规模。
-
测试用例优先级 [5]:当测试预算不足以执行完所有测试用例时,可 以基于特定优先级准则,对测试用例进行优先级排序以优化其执行次 序,旨在最大化优先级目标,例如测试用例集的缺陷检测速率。
web测试
功能测试 Functional Testing 根据产品特性和设计 需求,验证一个产品 的特性和行为是否满 足设计需求
功能测试常用步骤
- 根据需求来细分功能点
- 根据功能点派生测试需求
- 根据测试需求设计功能测试用例
- 逐项执行功能测试用例验证产品
相关的测试类型
- 正确性
- 产品功能是否与需求和设计文档一致
- 可靠性
- 用户交互是否引发软件崩溃和其它异常
- 易用性
- 软件产品完成特定任务的难易程度
功能测试示例
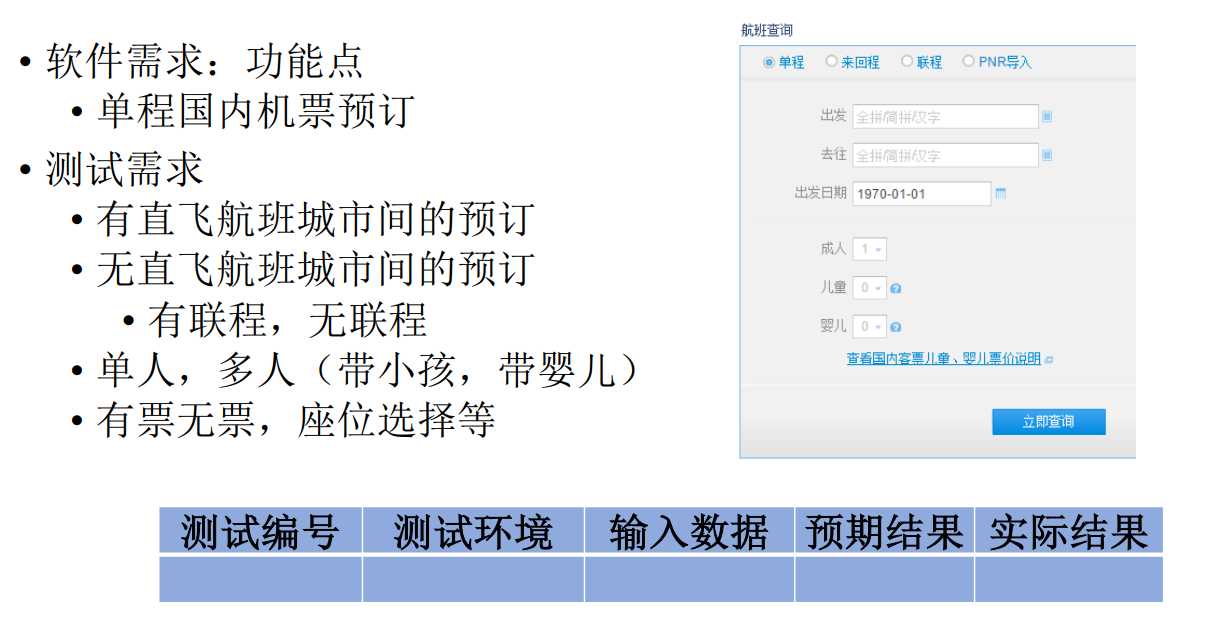
性能测试度量方法
- 不同的关注对象采用不同的性能的度量方法
- 服务端性能采用CPU、内存等使用率来度量
- 客户端性能通常根据系统处理特定用户请求的响 应时间来度量
性能测试度量对象
- 响应时间
- 并发用户数
- 吞吐量
- 性能计数器
负载测试
- 负载测试用于验证应用系统在正常负载条件下的行为
- 性能行为通过一些性能指标体现
- 两种方式:
- 直接到达负载数(如并发用户数,事务数等)
- 逐步增加负载数(如并发用户数,事务数等)
压力测试
- 压力测试是评估应用系统处于或超过预期负 载时的行为
- 压力测试关注的行为不一定是性能行为,可能是某种Bug,比如同步问题,内存泄露等
- 在压力级别逐渐增加时,系统性能应该按照预期缓慢下降,但是不应该崩溃
- 压力测试还可以发现系统崩溃的临界点,从而发现系统中的薄弱环节
Web功能测试方法
-
功能相关性
-
数据相关性
-
检查按钮的功能是否正确
-
字符串长度检查
-
字符类型检查
-
标点符号检查
-
特殊字符检查
-
中文字符处理
-
检查信息的完整性
-
信息重复
-
检查删除功能
-
检查添加和修改是否一致
-
重复提交表单
…
探索式测试方法
探索式测试(ET)是一种帮助测试人员如何在需求不完善的情况下 尽早发现更多软件质量风险的测试手段。
它是一种测试风格,测试思维,而不是具体的测试技术
产生过程
目前缺陷的检测有两种方式:自动化测试 和 手工测试。
- 自动化测试:
- a、有代码维护成本、学习成本,而且测试程序本身也存在问题。
- b、只要能在合理的场景中使用自动化还是能提高效率的,并不是所有的测试都 适合自动化。
- 手工测试:
- 需手脑并用,发挥聪明才智,才能设计出导致软件失效或符合软件设计效果的 真实场景。如果想发现与应用程序业务逻辑相关的缺陷手工测试是最佳选择。
- 缺点:
- a、慢
- b、无规律
- c、不易复现
- d、不可反复使用
- e、无可借鉴的经验
- 基于以上缺点诞生了手工测试的技术 ------ 探索式测试
指导方法
- 局部探索式测试法(小范围的,比如一个对话框等)
- 在运行任何一个测试用例时都都需要作出很多细微的战术层面决定
- 全局探索式测试法(总体测试,整个程序功能)
- 基于“漫游”概念,如同一个导游带领旅游团队参观大都市中的一系列 著名景点,漫游测试法提供的路线可以指导测试人员如何探索软件的方 方面面。
- 全局测试法对于制定完整的测试策略给出了指导意义
- 混合探索式测试法(把探索式测试的实质和使用脚本的手工测试 合并起来)
- 使用正式脚本可以为探索式测试设立一个明确框架范围,探索式测试可 以提高脚本测试的有效性,为脚本中的测试用例提供更多种多样的变化
众包测试
众包:利用群体力量来完成传统方法中成本高昂或耗时的大规模任务, 是Howe Jeff于2006年在美国《连线》杂志上首次提出的一种商业模式。
众包测试流程
- 申请上传:用户将自己的应用程序上传到 众测平台, 并指定相应的测试任务和酬劳信息。
- 任务选择和环境设置:众测人员自由选择他们想要完 成的任务。选择后测试人员从平台上下载应用程序进 行测试。
- 提交报告:众测人员根据选择的待测应用,对测试到 的缺陷提交缺陷报告。
- **生成最终测试报告:**平台收集补充信息,生成最终的 缺陷报告,包括:一般信息、设备信息、操作路径等。
- 报告验证:客户将验证所有最终的缺陷报告,并决定 如何酬劳每个提交报告的众包测试人员
众包测试的优势
- 更充分的测试时间
- 更广泛的测试方法
- 更多样的测试环境
- 更全面的测试方法
众包测试中的缺陷类型
- 功能缺陷
- 显示问题
- 性能问题
- 布局问题
- 应用崩溃
- 错误提示
- 空白屏
众包测试面临的挑战
- 任务分配
- 任务奖励
- 众测过程引导
- 测试报告质量控制
协作式众包测试
- 信息共享:用户在提交报告时进行实时相似报告推荐,避免重复报告提交。
- 任务分配:审核页面推荐待审核的报告列表,测试页面推荐待测页面。
- 协作方式:点赞点踩操作:利用用户的交叉审核,验证报告有效性。
- 一键Fork:Fork他人结果后进行修改,利用多人协作提升报告质量。
测试报告

众测报告信息
- 缺陷截图
- 文本描述
- 缺陷行为描述、复现步骤、期望行为
- 测试环境信息
众测报告聚合
大量的测试报告——较多的重复数据
- 懒惰和缺乏经验的用户。
- 测试报告搜索功能较差。
- 偶然的重复——由于网络等原因不小心提交了多次
- 给开发者增加了许多工作量。
- 不同的信息可以使开发者对Bug有一个更全面的了解。
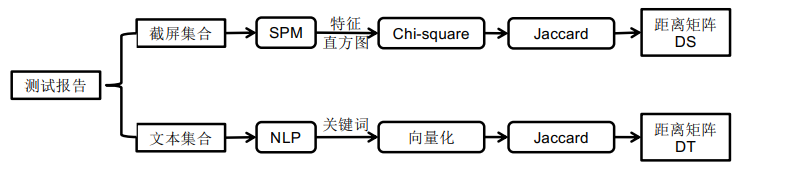
Aggregator
- 截屏集合的距离矩阵DS计算
- 文本集合的距离矩阵DT计算
- 距离矩阵的合并–Balanced Distance的计算
- 若文本完全相同,则认为平衡距离为0
- 若截屏完全相同,则平衡距离为加权的文本距离
- 文本和截屏均不相同时,使用二者的调和平均数
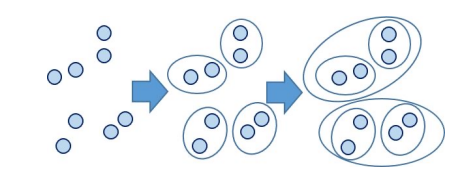
- 合成层次聚类( Agglomerative Hirarchical Clustering )
- 将所有样本点各自归为一类,两两类别计算距离
- 将距离最短的两个类合成一个类,计算新类与旧类的距离
- 重复操作
- 直至所有样本点都归于一类
Summarizer
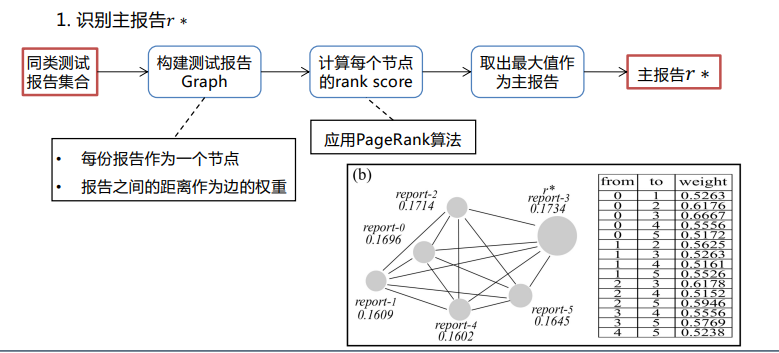

众测报告排序
- 使用文本+图片结合分析的方法
- 通过自然语言处理算法计算文本的相似度
- 通过SPM算法(Spatial Pyramid Matching)识别缺陷截图相似度
- 通过使用一种多目标的优化算法结合文本与截图相似度完成针对测试报告的相似度比较
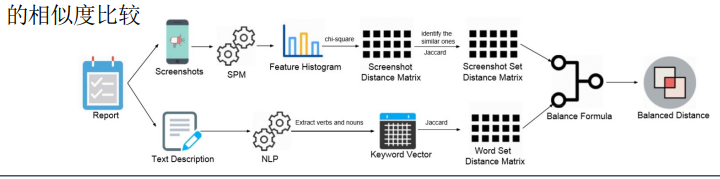
处理截图主要涉及三个操作:
- 建立特征直方图
- 计算截图之间的距离
- 计算截图集合之间的距离
- 将图片转化为特征向量便于计算
处理文本主要涉及两个操作:
- 关键词的提取 过滤无用词汇:这些词会对文本距离计算产生消极影响
- 文本距离的计算 使用Jaccard距离计算测试报告集 中文本描述间距离
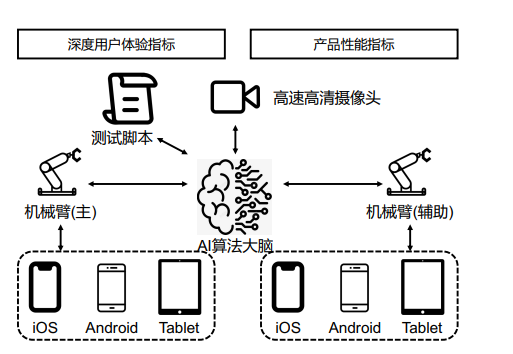
移动应用自动化 GUI 测试
GUI测试 = 控件定位 / 匹配 + 操作执行
自动化测试框架
-
Selenium
- Selenium 是一个开源的自动化测试工具,专门用于自动化网 页浏览器的操作。
- Selenium 允许测试人员使用多种编程语言编写测试脚本(如 Java、C#、Python、Ruby、JavaScript 等),以模拟用户 对网页的各种操作,如点击、填写表单、导航等
-
Appium
- Appium 是一个扩展了 Selenium 的 WebDriver 协议来支持移 动应用自动化的工具,允许使用 Selenium 的客户端库来编写 适用于 iOS 和 Android 应用的测试脚本
人工录制 + 自动化回放
基于模型的自动化测试技术
基于图像的简单控件定位
Sikuli 来自 MIT 的 Sikuli 通过图像 匹配算法来完成对 GUI 元素 的识别和定位。
Airtest 来自网易的 Airtest 连接到某个窗 口或移动设备上,然后进行 GUI 测试脚本的编写。
存在的问题
-
测试脚本的执行仍依赖于操作系统接口,如 Android 的 ADB
-
使用像素级方式定位控件的方式难以应对复杂场景,如不同分辨率的设备
-
仍面临人工编写和维护脚本的成本
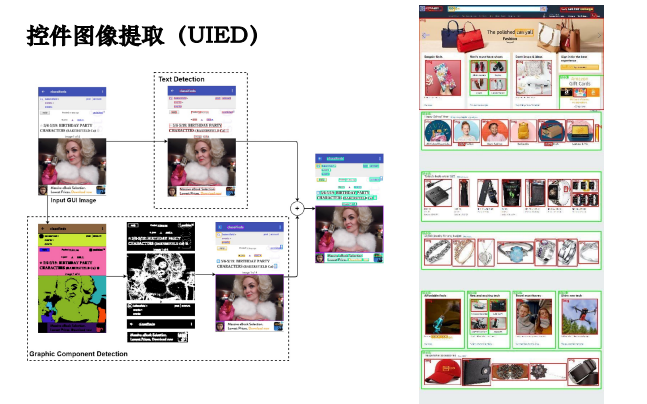
深度图像理解(控件提取)
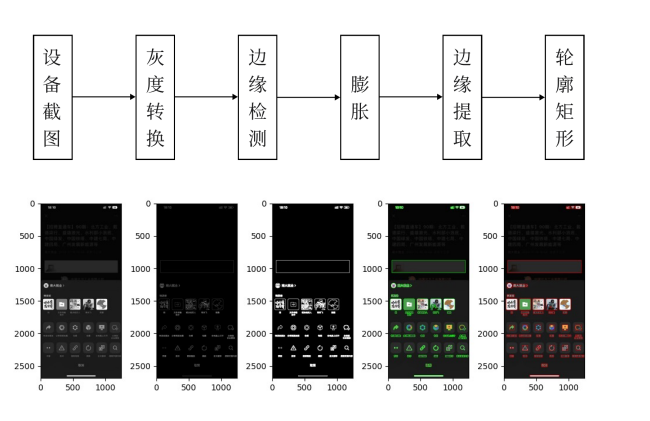
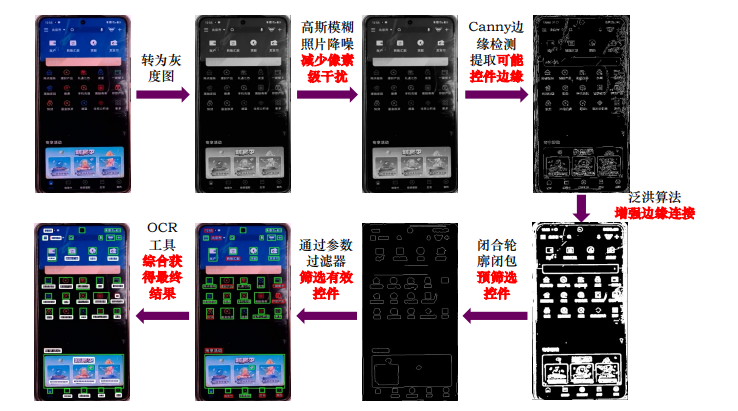
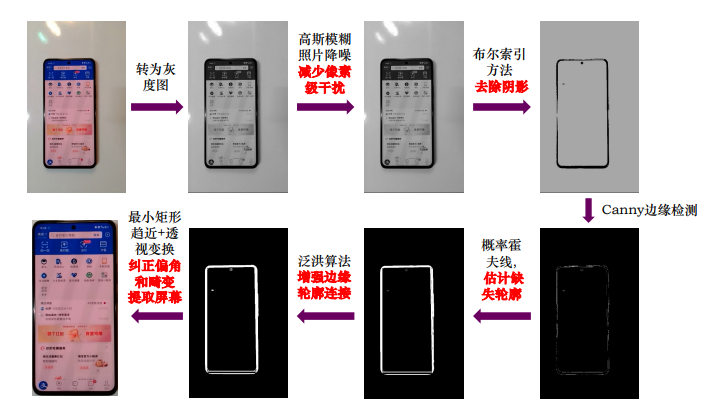
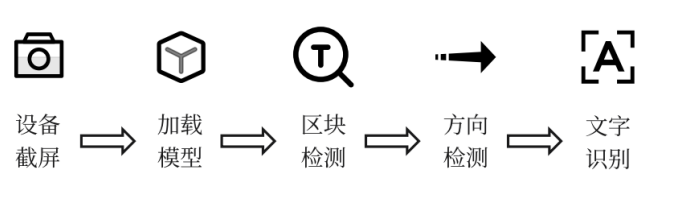
深度图像理解(文字识别 )
深度图像理解(界面理解)
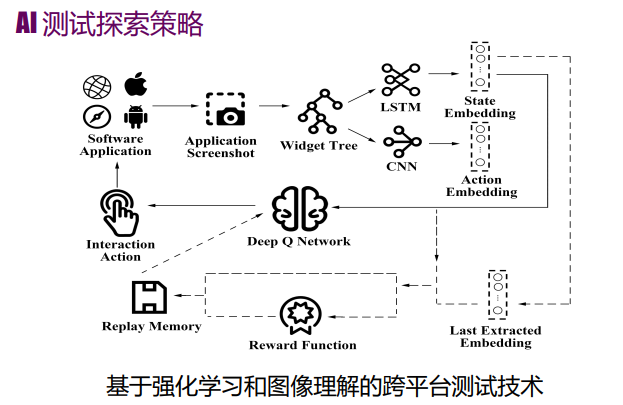
基于深度图像理解的自动化探索工具
- 无法感知异形屏幕对 UI 控件的遮挡
- 难以模拟真实场景下人的交互操作
- 仍依赖操作系统接口执行测试操作

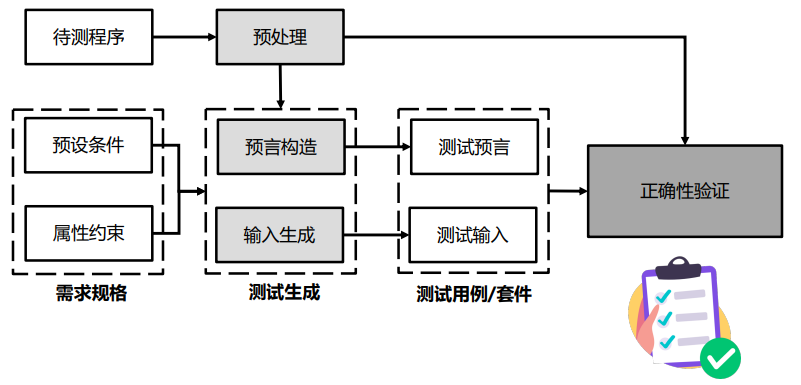
测试预言问题
测试预言
测试预言定义(Test Oracle)
- 是文档:体现被测单元的预期功能1(Intended Functionality)
- 被测单元:模块、类、方法、函数、语句
- 是机制:验证待测程序的行为是否符合预期
- 是程序:判定程序的执行是否违反了某种正确性政策
- 是约束:
- 是映射:

测试预言分类
- 隐式预言:用于检测**显著缺陷(Obvious Bug)**的测试预言。例如, 预期外的程序崩溃(Crash)就是一种典型的显著缺陷。
- 显式预言:根据软件的预期功能提取得到的预言,一般用于检测功能性缺陷(Functional Bug)。
显式预言如上图举例
隐式预言如下图

预言问题:
给定系统的输入,如何找到能够正确辨别出符合期望的 正确行为与发现潜在的不正确行为测试预言的挑战性难题。
预言问题具有挑战性的原因
- 缺少清晰的规格:文档通常用自然语言编写,而自然语言存在二义性
- 软件的动态特征:网络问题导致的问题、线程调度产生的并发问题
- 优先的测试资源:测试预言空间和测试输入空间一样无法穷尽
预言问题现状
复杂的预言难以构建,容易构建的预言效果差
预言问题解决方案
利用静态程序分析手段自动化构建测试预言
- 从文本文档/注释中自动提取(Specification Mining)
- 设计形式化的文档语言:体系结构设计语言(ADL)
- 使用不完全测试预言(Partial Test Oracle)
- 蜕变测试(Metamorphic Testing)
- 差分测试(Differential Testing)
蜕变测试
蜕变关系(Metamorphic Relation, MR) 是指多次执行目标程序时,输入与输出之间期望遵循的关系。
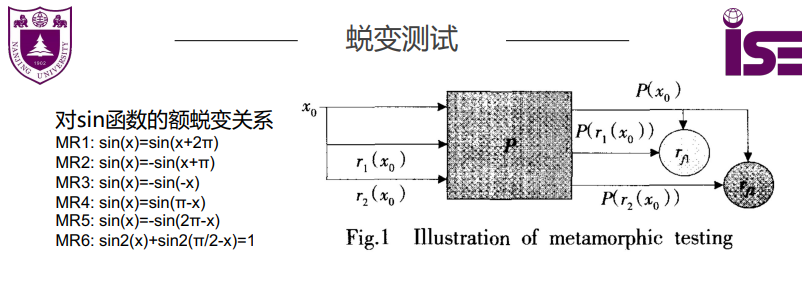
应对(自动化)软件测试中的两大难题
- 可靠测试集问题(Reliable Test Set Problem) 测试生成/扩增
- 预言问题(Oracle Problem)正确性验证
蜕变测试本质:充分利用成功测试用例
- 对成功测试用例表现出的必要属性(Necessary Properties) 的复用;
- 必要属性:从相关成功测试用例的集合和程序规格中提取出的、 待测软件必须遵守的属性;
- 属性的必要性:违反必要属性的测试一定发现了某种软件缺陷。
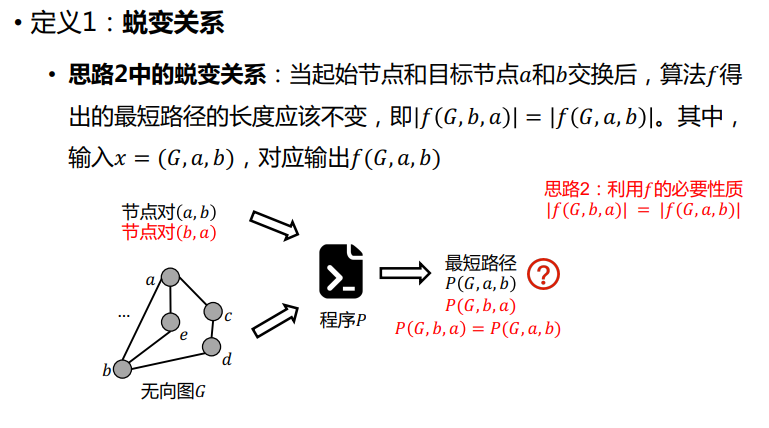
三要素
蜕变关系(MR, Metamorphic Relation)
一组待测算法/功能 的必要属性,蜕变测试的核心
蜕变关系可以是非等式关系
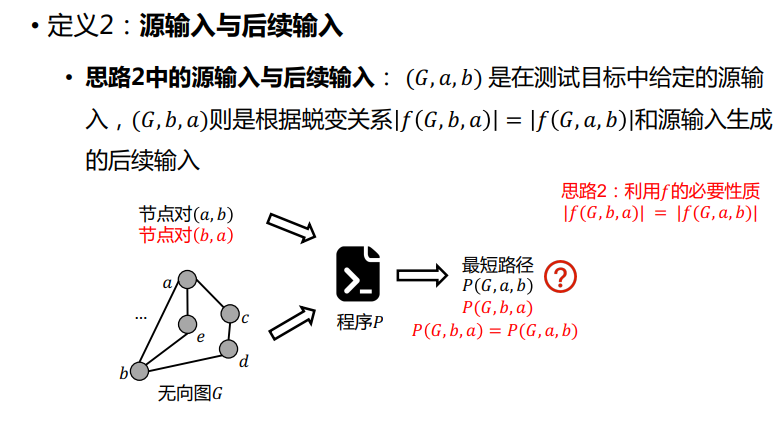
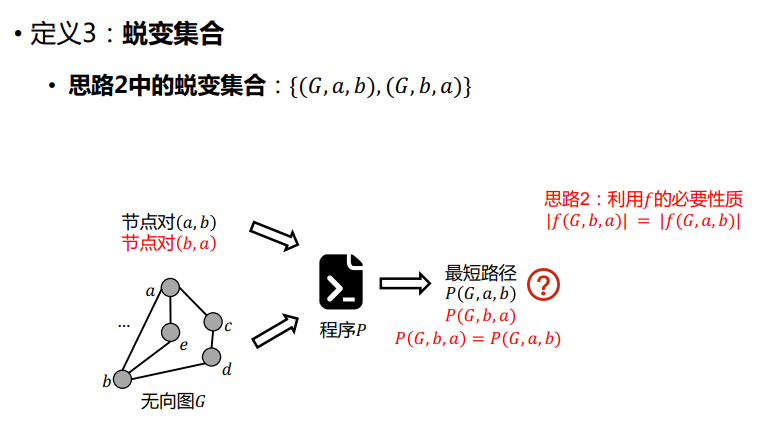
蜕变集合(Metamorphic Group)
由表达了蜕变关系的一组测试输入组成的集合
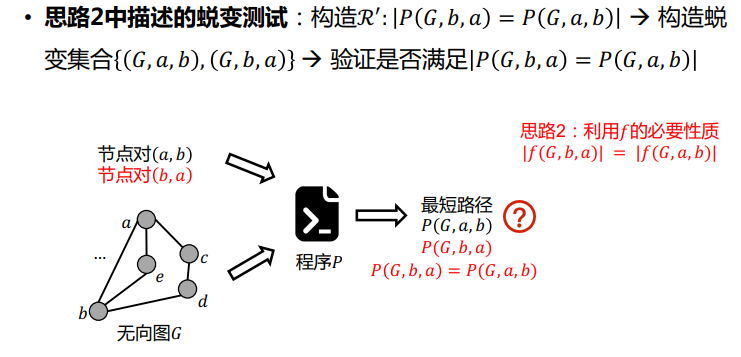
蜕变测试过程
应用蜕变关系和蜕变集合进行测试的一般流程
例子



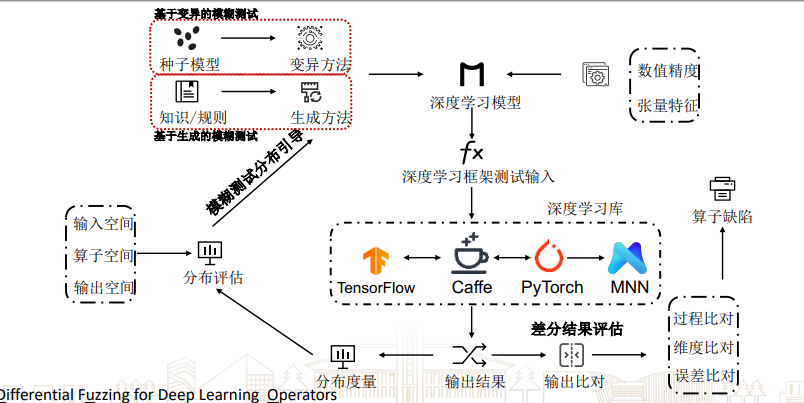
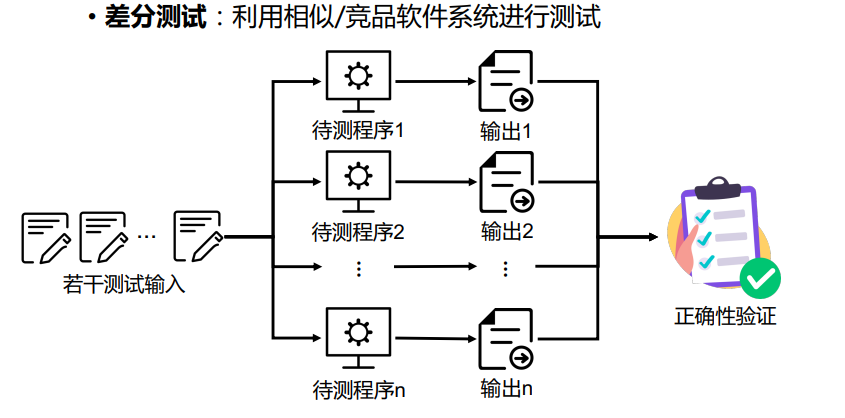
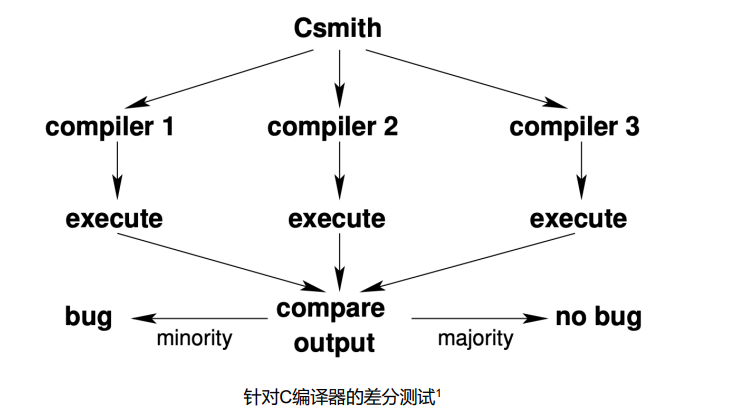
差分测试
基本思想:通过将同一测试用例运行到一系列相似功能的应用中观察执行差异来检测bug。
定义
差分测试(Differential Testing)也称为差分模糊测试,是 一种常用的软件测试技术,通过向一系列类似的应用程序 (或同一应用程序的不同实现)提供相同的输入,根据这些相似程序执行结 果是否存在差异来判定是否检测到缺陷1,2。
蜕变和差分测试的辨析
- 相同点:
- 都利用了待测程序中的必要属性(Necessary Property);
- 都是黑盒测试技术
- 不同点
- 必要属性的类型不同:
- 蜕变测试利用了单一待测程序的必要属性;
- 差分 测试则利用了多个相似待测程序间的必要属性;
- 正确性验证的准则不同:
- 蜕变测试的正确性验证准则是可变的,由蜕变关系决定;
- 差分测试的正确性准则是固定的,即不同相似待测程序在同 一测试输入上的输出结果应该相同
- 必要属性的类型不同:
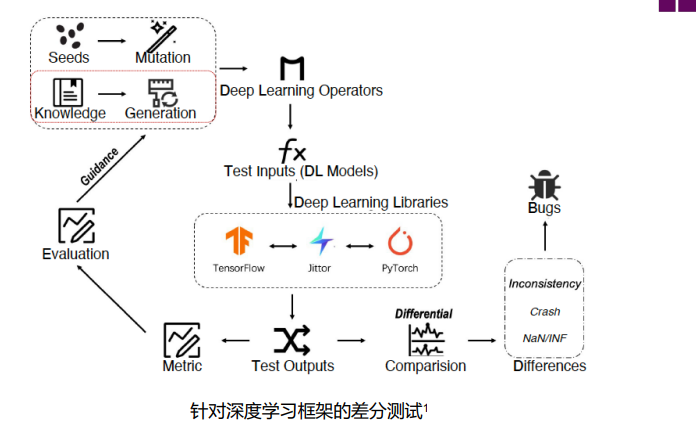
智能软件测试
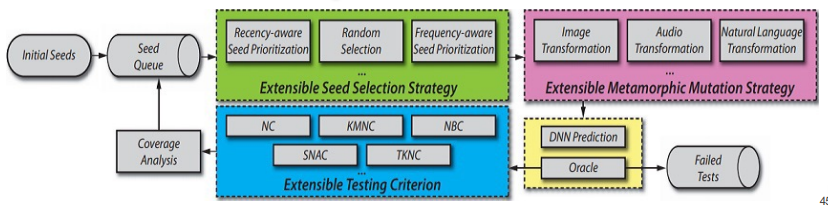
测试标准
- Neuron Coverage
- k-Multisection Neuron Coverage
- Neuron Boundary Coverage
- Strong Neuron Activation Coverage
- Top-k Neuron Coverage
数据扩增
数据扩增:通过轻微变换现有数据或创建新的合成图像来得到新数 据的技术。应用领域有图像扩增、文本扩增、雷达扩增……
突变测试
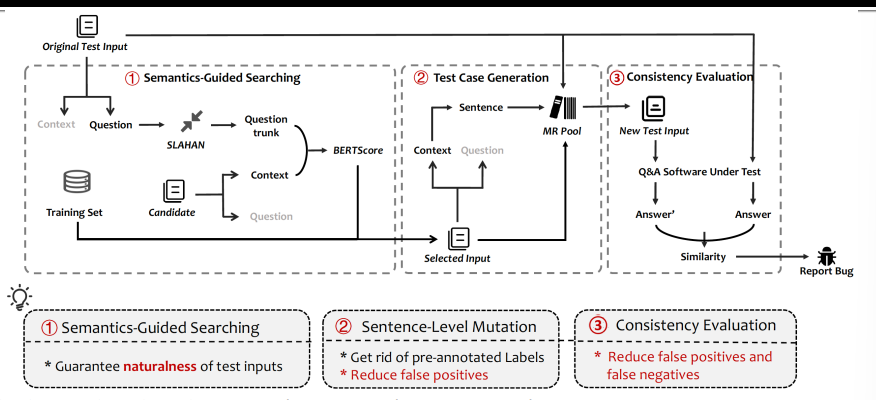
标准
- 鲁棒性
- 后门攻击
- 公平性
- 可解释性AI
- 隐私性
Framework / Library Testing