# ch18-codegen-riscv-RISC-V 概述
RISC: Reduced Instruction Set Computer (精简指令集计算机)
V: Five
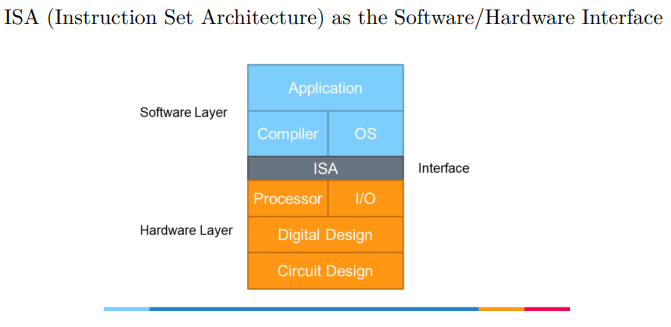
- ISA是向上层提供的接口
- cpu是ISA的硬件实现
- 提供指令、数据类型、寄存器
- 2017 ACM Turing Award
“RISC-V 很可能发展成为世界主流 CPU 之一, 在 CPU 领域形成 Intel、 ARM、RISC-V 三分天下的格局。” — 中国工程院院士 倪光南
# 如何用RISC-V写代码
只涉及32位,只涉及整数
# add.asm
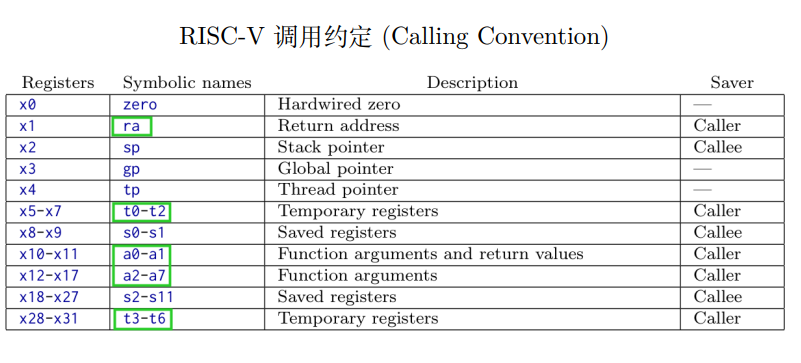
第一列是别名,总共32个寄存器
- x0:zero:存0,不可修改
- x1:ra:专门存放返回地址(函数调用返回地址)
- t0-t6:保存临时变量
- pc:program counter,下一条指令的地址
- RISC-V所有运算都在寄存器中
指令
- li t0, 20 #li: load immediate
- li t1,22
- add t2, t0, t1 #t2 = t0 + t1
- li是伪指令,语法糖
- addi x5, x0, 20是基本指令
# add-sub.asm
- li t0, 0
- li t1, 10
- add t2, t0, t1
- li t3, 30
- li t4, 40
- add t5, t3, t4
- sub t6, t2, t5
# ecall.asm 系统调用
分四步:
- 系统调用编号存入a7
- 准备参数
- 调用ecall
- 准备返回值
li t0, 0
li t1, 10
add t2, t0, t1
li t3, 30
li t4, 40
add t5, t3, t4
sub t6, t2, t5
li a7, 1
add a0, t6, zero #mov伪指令的实现
#mov a0, t6
ecall
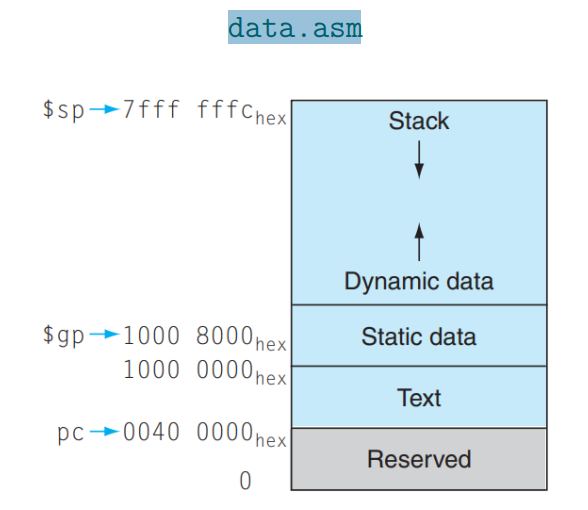
# data.asm
把数据和操作分开
- la
- lw
- sw
- a0是参数寄存器
.data
g: .word 0 #.word是汇编指令,一个word是4byte,half是2byte,dword是2words
#g是label,是地址的标号,可以取地址
h: .word 10
i: .word 30
j: .word 40
result: .word 0
msg: .string "the result is :" #.ascii不会自动在末尾加\0
.text
la t0, g #load address,把g所对应的地址放入t0
lw t0,0(to) #load word,从t0+0(偏移量)取值一个word大小的值放入t0,偏移量是为了数组取值
la t1, h
lw t1,0(t1)
add t2, t0, t1
la t3, i
lw t3,0(t3)
la t4, j
lw t4,0(t4)
add t5, t3, t4
sub t6, t2, t5
#往内存放数据
la t0, result
sw t6. 0(t0) #store word
#打印出来
li a7, 4
la a0, msg #a0是参数
ecall
li a7, 4
mv a0, t6
ecall
# array.asm
.data
numbers: .word -30, 30, -20, 20, -10, 10, 0
.text
#修改一个值20:3 * 4偏移12byte
la t0, numbers
lw t1, 12(t0)
addi t1, t1, 80
sw t1, 12(t0)
# branch-max.asm
- j:无条件跳转,伪指令
.data
a: .word 100
b: .word 200
c: .word 0
.text
la t0, a
lw t0, 0(t0)
la t0, b
lw t0, 0(t0)
bge t0, t1, greater_equal #如果t0 >= t1,就跳转到greater_equal标签
#t0 < t1
mv t2, t1
j end #j:"jump"
greater_equal:
mv t2, t0 #用t2保存最大值
end:
la t3, c
sw t2, 0(t3) #存入c
# for.asm
- slli
- bltz
.data
numbers: .word -30, 30, -20, 20, -10, 10, 0
size: .word 7
positive_sum: .word 0
negative_sum: .word 0
.text
la t0, numbers #t0: the address of the array数组首地址
lw t1, size
mv t2, zero #counter ,initially 0
li t3, 0 #t3: sum of positive numbers <- 0
li t4, 0 #t4: sum of negative numbers <- 0
loop:
bge t2, t1, end_loop
#numbers[t2]
# mul t5, t2, 4 #t5= t2 * 4
# t2向左移两位
slli t5, t2, 2 #slli:shift left logic immediate
add t5, t0. t5
lw t5, 0(t5) #t5中为当前访问的值
addi t2, t2, 1
bltz t5, negative #branch if less than zero
add t3, t3, t5
j loop
negative:
add t4, t4, t5
j loop
end_loop:
la t5, positive_sum
sw t3, 0(t5)
la t5, negative_sum
sw t4, 0(t5)
# proc-max.asm函数调用
- jal
- a0, a1同时用作返回值和传参
.data
max_result: .word 0
.text
.global main
max:
blt a0, a1, smaller #a0 < a1
j end_max
smaller:
mv a0, a1
end_max:
ret
#jalr ra
#jalr zero 0(ra) #jalr : jump and link reister 根据ra保存的地址,跳转到ra所在地址,同时不关心这条指令的下一条指令的地址,所以扔掉到zero里
####### main #########
.data
a: .word 100
b: .word 200
.text
main:
#先准备好参数,传入a0-a7,再call
lw a0, a
lw a1, b
call max
#jal max
#jal ra, max #jal: jump and link, ra专门存返回地址,转移控制权,保存返回地址
#ra放了max的返回值
sw a0, max_result, t0
# proc-fact.asm递归
.text
.global main
factorial:
beqz a0, base_case
#stack high->low
#sp stack pointer
addi sp, sp, -8 #入栈保护
sw a0, -4(sp)
sw ra, 0(sp)
# n > 0: n * factorial(n - 1)
addi a0, a0, -1 #a0 = n - 1
call factorial #a0 : factorial(n - 1)
mv t0, a0 #t0: factorial(n - 1)
lw a0, 4(sp) #a0 = n = stack[sp + 4]
lw ra, 0(sp) #ra = stack[sp]
addi sp, sp, 8 #栈清空
mul a0, a0, t0 #a0 = n * factorial(n - 1)
j end
base_case:
li a0, 1
end:
ret
######## main ############
.data
a: .word 10
.text
main:
lw a0, n
call factorial
# bubblesort
/* Type your code here, or load an example. */
int square(int num) {
return num * num;
}
#include <stdio.h>
int numbers[] = {20, 3, 56, 8, 90};
int size = 5;
void Sort(int v[], int n);
void Swap(int v[], int k);
void Print(int v[], int n);
int main() {
Sort(numbers, size);
}
void Sort(int v[], int n) {
for (int i = 0; i < n; i++) {
for (int j = i - 1; j >= 0 && v[j] > v[j + 1]; j--) {
Swap(v, j);
}
}
}
void Swap(int v[], int k) {
int temp;
temp = v[k];
v[k] = v[k + 1];
v[k + 1] = temp;
}
void Print(int v[], int n) {
for (int i = 0; i < n; i++) {
printf("%d\n", v[i]);
}
}
asm
square:
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], edi
mov eax, DWORD PTR [rbp-4]
imul eax, eax
pop rbp
ret
numbers:
.long 20
.long 3
.long 56
.long 8
.long 90
size:
.long 5
main:
push rbp
mov rbp, rsp
mov eax, DWORD PTR size[rip]
mov esi, eax
mov edi, OFFSET FLAT:numbers
call Sort
mov eax, 0
pop rbp
ret
Sort:
push rbp
mov rbp, rsp
sub rsp, 32
mov QWORD PTR [rbp-24], rdi
mov DWORD PTR [rbp-28], esi
mov DWORD PTR [rbp-4], 0
jmp .L6
.L10:
mov eax, DWORD PTR [rbp-4]
sub eax, 1
mov DWORD PTR [rbp-8], eax
jmp .L7
.L9:
mov edx, DWORD PTR [rbp-8]
mov rax, QWORD PTR [rbp-24]
mov esi, edx
mov rdi, rax
call Swap
sub DWORD PTR [rbp-8], 1
.L7:
cmp DWORD PTR [rbp-8], 0
js .L8
mov eax, DWORD PTR [rbp-8]
cdqe
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov edx, DWORD PTR [rax]
mov eax, DWORD PTR [rbp-8]
cdqe
add rax, 1
lea rcx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rcx
mov eax, DWORD PTR [rax]
cmp edx, eax
jg .L9
.L8:
add DWORD PTR [rbp-4], 1
.L6:
mov eax, DWORD PTR [rbp-4]
cmp eax, DWORD PTR [rbp-28]
jl .L10
nop
nop
leave
ret
Swap:
push rbp
mov rbp, rsp
mov QWORD PTR [rbp-24], rdi
mov DWORD PTR [rbp-28], esi
mov eax, DWORD PTR [rbp-28]
cdqe
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov eax, DWORD PTR [rax]
mov DWORD PTR [rbp-4], eax
mov eax, DWORD PTR [rbp-28]
cdqe
add rax, 1
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov edx, DWORD PTR [rbp-28]
movsx rdx, edx
lea rcx, [0+rdx*4]
mov rdx, QWORD PTR [rbp-24]
add rdx, rcx
mov eax, DWORD PTR [rax]
mov DWORD PTR [rdx], eax
mov eax, DWORD PTR [rbp-28]
cdqe
add rax, 1
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rdx, rax
mov eax, DWORD PTR [rbp-4]
mov DWORD PTR [rdx], eax
nop
pop rbp
ret
.LC0:
.string "%d\n"
Print:
push rbp
mov rbp, rsp
sub rsp, 32
mov QWORD PTR [rbp-24], rdi
mov DWORD PTR [rbp-28], esi
mov DWORD PTR [rbp-4], 0
jmp .L13
.L14:
mov eax, DWORD PTR [rbp-4]
cdqe
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov eax, DWORD PTR [rax]
mov esi, eax
mov edi, OFFSET FLAT:.LC0
mov eax, 0
call printf
add DWORD PTR [rbp-4], 1
.L13:
mov eax, DWORD PTR [rbp-4]
cmp eax, DWORD PTR [rbp-28]
jl .L14
nop
nop
leave
ret